Notes
A personal collection of notes and cheatsheets.
Source code is located at johannst/notes.
Shells
zsh(1)
Keybindings
Change input mode:
bindkey -v change to vi keymap
bindkey -e change to emacs keymap
Define key-mappings:
bindkey list mappings in current keymap
bindkey in-str cmd create mapping for `in-str` to `cmd`
bindkey -r in-str remove binding for `in-str`
# C-v <key> dump <key> code, which can be used in `in-str`
# zle -l list all functions for keybindings
# man zshzle(1) STANDARD WIDGETS: get description of functions
Access edit buffer in zle widget:
$BUFFER # Entire edit buffer content
$LBUFFER # Edit buffer content left to cursor
$RBUFFER # Edit buffer content right to cursor
# create zle widget which adds text right of the cursor
function add-text() {
RBUFFER="some text $RBUFFER"
}
zle -N add-text
bindkey "^p" add-text
Parameter
Default value:
# default value
echo ${foo:-defval} # defval
foo=bar
echo ${foo:-defval} # bar
Alternative value:
echo ${foo:+altval} # ''
foo=bar
echo ${foo:+altval} # altval
Check variable set, error if not set:
echo ${foo:?msg} # print `msg` and return errno `1`
foo=bar
echo ${foo:?msg} # bar
Sub-string ${var:offset:length}:
foo=abcdef
echo ${foo:1:3} # bcd
Trim prefix ${var#prefix}:
foo=bar.baz
echo ${foo#bar} # .baz
Trim suffix ${var%suffix}:
foo=bar.baz
echo ${foo%.baz} # bar
Substitute pattern ${var/pattern/replace}:
foo=aabbccbbdd
echo ${foo/bb/XX} # aaXXccbbdd
echo ${foo//bb/XX} # aaXXccXXdd
# replace prefix
echo ${foo/#bb/XX} # aabbccbbdd
echo ${foo/#aa/XX} # XXbbccbbdd
# replace suffix
echo ${foo/%bb/XX} # aabbccbbdd
echo ${foo/%dd/XX} # aabbccbbXX
Note:
prefix/suffix/patternare expanded as pathnames.
Variables
# Variable with local scope
local var=val
# Read-only variable
readonly var=bal
Indexed arrays:
arr=(aa bb cc dd)
echo $arr[1] # aa
echo $arr[-1] # dd
arr+=(ee)
echo $arr[-1] # ee
echo $arr[1,3] # aa bb cc
Associative arrays:
typeset -A arr
arr[x]='aa'
arr[y]='bb'
echo $arr[x] # aa
Tied arrays:
typeset -T VEC vec=(1 2 3) '|'
echo $vec # 1 2 3
echo $VEC # 1|2|3
Unique arrays (set):
typeset -U vec=(1 2 3)
echo $vec # 1 2 3
vec+=(1 2 4)
echo $vec # 1 2 3 4
Expansion Flags
Join array to string j:sep::
foo=(1 2 3 4)
echo ${(j:-:)foo} # 1-2-3-4
echo ${(j:\n:)foo} # join with new lines
Split string to array s:sep:
foo='1-2-3-4'
bar=(${(s:-:)foo}) # capture as array
echo $bar # 1 2 3 4
echo $bar[2] # 2
Upper/Lower case string:
foo=aaBB
echo ${(L)foo} # aabb
echo ${(U)foo} # AABB
Key/values in associative arrays:
typeset -A vec; vec[a]='aa'; vec[b]='bb'
echo ${(k)vec} # a b
echo ${(v)vec} # aa bb
echo ${(kv)vec} # a aa b bb
# Iterate over key value pairs.
for k v in ${(kv)vec)}; do ...; done
I/O redirections
Process substitution
Process substitution allows to redirect the stdout of multiple processes at once.
vim -d <(grep foo bar) <(grep foo moose)
Argument parsing with zparseopts
zparseopts [-D] [-E] [-A assoc] specs
Arguments are copied into the associative array assoc according to specs.
Each spec is described by an entry as opt[:][=array].
optis the option without the-char. Passing-fis matched againstfopt,--longis matched against-long.- Using
:means the option will take an argument. - The optional
=arrayspecifies an alternate storage container where this option should be stored.
Documentation can be found in
man zshmodules.
Example
#!/bin/zsh
function test() {
zparseopts -D -E -A opts f=flag o: -long:
echo "flag $flag"
echo "o $opts[-o]"
echo "long $opts[--long]"
echo "pos $1"
}
test -f -o OPTION --long LONG_OPT POSITIONAL
# Outputs:
# flag -f
# o OPTION
# long LONG_OPT
# pos POSITIONAL
Regular Expressions
Zsh supports regular expression matching with the binary operator =~.
The match results can be accessed via the $MATCH variable and
$match indexed array:
$MATCHcontains the full match$match[1]contains match of the first capture group
INPUT='title foo : 1234'
REGEX='^title (.+) : ([0-9]+)$'
if [[ $INPUT =~ $REGEX ]]; then
echo "$MATCH" # title foo : 1234
echo "$match[1]" # foo
echo "$match[2]" # 1234
fi
Trap Handling
trap "<CMDs>" <SIG>/EXIT
# Show current trap handler.
trap -p
# List signal names.
trap -l
Example: Run handler only on error exit
trap 'test $? -ne 0 && echo "run exit trap"' EXIT
# -> no print
exit 0
# -> print
exit 1
Example: Mutex in shell script
For example if a script is triggered in unsynchronized, we may want to ensure that a single script instance runs.
# open file=LOCK with fd=100
exec 100>LOCK
# take exclusive lock, wait maximal for 3600s
flock -w 3600 -x 100 || { echo "flock timeout"; exit 1; }
# eg automatically release lock when script exits
trap "flock -u 100" EXIT
Completion
Installation
Completion functions are provided via files and need to be placed in a location
covered by $fpath. By convention the completion files are names as _<CMD>.
A completion skeleton for the command foo, stored in _foo
#compdef _foo foo
function _foo() {
...
}
Alternatively one can install a completion function explicitly by calling compdef <FUNC> <CMD>.
Completion Variables
Following variables are available in Completion functions:
$words # array with command line in words
$#words # number words
$CURRENT # index into $words for cursor position
$words[CURRENT-1] # previous word (relative to cursor position)
Completion Functions
_describesimple completion, just words + description_argumentssophisticated completion, allow to specify actions
Completion with _describe
_describe MSG COMP
MSGsimple string with header messageCOMParray of completions where each entry is"opt:description"
function _foo() {
local -a opts
opts=('bla:desc for bla' 'blu:desc for blu')
_describe 'foo-msg' opts
}
compdef _foo foo
foo <TAB><TAB>
-- foo-msg --
bla -- desc for bla
blu -- desc for blu
Completion with _arguments
_arguments SPEC [SPEC...]
where SPEC can have one of the following forms:
OPT[DESC]:MSG:ACTIONfor option flagsN:MSG:ACTIONfor positional arguments
Available actions
(op1 op2) list possible matches
->VAL set $state=VAL and continue, `$state` can be checked later in switch case
FUNC call func to generate matches
{STR} evaluate `STR` to generate matches
Example
Skeleton to copy/paste for writing simple completions.
Assume a program foo with the following interface:
foo -c green|red|blue -s low|high -f <file> -d <dir> -h
The completion handler could be implemented as follows in a file called _foo:
#compdef _foo foo
function _foo_color() {
local colors=()
colors+=('green:green color')
colors+=('red:red color')
colors+=('blue:blue color')
_describe "color" colors
}
function _foo() {
_arguments \
"-c[define color]:color:->s_color" \
"-s[select sound]:sound:(low high)" \
"-f[select file]:file:_files" \
"-d[select dir]:dir:_files -/" \
"-h[help]"
case $state in
s_color) _foo_color;;
esac
}
Example with optional arguments
For this example we assume that the command foo takes at least three optional
arguments such as
foo arg1 arg2 arg3 [argN..]
function _foo() {
_arguments \
"1:opt 1:(a b c)" \
":opt next:(d e f)" \
"*:opt all:(u v w)"
}
Explanation:
1:MSG:ACTIONsets completion for the first optional argument:MSG:ACTIONsets completion for the next optional argument*:MSG:ACTIONsets completion for the optional argument where none of the previous rules apply, so in our example forarg3, argN...
_filesis a zsh builtin utility function to complete files/dirs see
bash(1)
Expansion
Generator
# generate sequence from n to m
{n..m}
# generate sequence from n to m step by s
{n..m..s}
# expand cartesian product
{a,b}{c,d}
Parameter
# default value
bar=${foo:-some_val} # if $foo set, then bar=$foo else bar=some_val
# alternate value
bar=${foo:+bla $foo} # if $foo set, then bar="bla $foo" else bar=""
# check param set
bar=${foo:?msg} # if $foo set, then bar=$foo else exit and print msg
# indirect
FOO=foo
BAR=FOO
bar=${!BAR} # deref value of BAR -> bar=$FOO
# prefix
${foo#prefix} # remove prefix when expanding $foo
# suffix
${foo%suffix} # remove suffix when expanding $foo
# substitute
${foo/pattern/string} # replace pattern with string when expanding foo
# pattern starts with
# '/' replace all occurences of pattern
# '#' pattern match at beginning
# '%' pattern match at end
# set programmatically with priintf builtin
printf -v "VAR1" "abc"
NAME=VAR2
printf -v "$NAME" "%s" "def"
Note:
prefix/suffix/patternare expanded as pathnames.
Pathname
* match any string
? match any single char
\\ match backslash
[abc] match any char of 'a' 'b' 'c'
[a-z] match any char between 'a' - 'z'
[^ab] negate, match all not 'a' 'b'
[:class:] match any char in class, available:
alnum,alpha,ascii,blank,cntrl,digit,graph,lower,
print,punct,space,upper,word,xdigit
With extglob shell option enabled it is possible to have more powerful
patterns. In the following pattern-list is one ore more patterns separated
by | char.
?(pattern-list) matches zero or one occurrence of the given patterns
*(pattern-list) matches zero or more occurrences of the given patterns
+(pattern-list) matches one or more occurrences of the given patterns
@(pattern-list) matches one of the given patterns
!(pattern-list) matches anything except one of the given patterns
Note:
shopt -s extglob/shopt -u extglobto enable/disableextgloboption.
I/O redirection
Note: The trick with bash I/O redirection is to interpret from left-to-right.
# stdout & stderr to file
command >file 2>&1
# equivalent
command &>file
# stderr to stdout & stdout to file
command 2>&1 >file
The article Bash One-Liners Explained, Part III: All about redirections contains some nice visualization to explain bash redirections.
Explanation
j>&i
Duplicate fd i to fd j, making j a copy of i. See dup2(2).
Example:
command 2>&1 >file
- duplicate
fd 1tofd 2, effectively redirectingstderrtostdout - redirect
stdouttofile
Process substitution (ref)
Process substitution allows to redirect the stdout of multiple processes at once.
vim -d <(grep foo bar) <(grep foo moose)
Command grouping
Execute commands in a group with or without subshell. Can be used to easily redirect stdout/stderr of all commands in the group into one file.
# Group commands without subshell.
v=abc ; { v=foo; echo $v; } ; echo $v
# foo
# foo
# Group commands with subshell.
v=abc ; ( v=foo; echo $v; ) ; echo $v
# foo
# abc
Trap Handling
trap "<CMDs>" <SIG>/EXIT
# Show current trap handler.
trap -p
# List signal names.
trap -l
Example: Run handler only on error exit
trap 'test $? -ne 0 && echo "run exit trap"' EXIT
# -> no print
exit 0
# -> print
exit 1
Example: Mutex in shell script
For example if a script is triggered in unsynchronized, we may want to ensure that a single script instance runs.
# open file=LOCK with fd=100
exec 100>LOCK
# take exclusive lock, wait maximal for 3600s
flock -w 3600 -x 100 || { echo "flock timeout"; exit 1; }
# eg automatically release lock when script exits
trap "flock -u 100" EXIT
Argument parsing with getopts
The getopts builtin uses following global variables:
OPTARG, value of last option argumentOPTIND, index of the next argument to process (user must reset)OPTERR, display errors if set to1
getopts <optstring> <param> [<args>]
<optstring>specifies the names of supported options, egf:cf:means-foption with an argumentcmeans-coption without an argument
<param>specifies a variable name whichgetoptsfills with the last parsed option argument<args>optionally specify argument string to parse, by defaultgetoptsparses$@
Example
#!/bin/bash
function parse_args() {
while getopts "f:c" PARAM; do
case $PARAM in
f) echo "GOT -f $OPTARG";;
c) echo "GOT -c";;
*) echo "ERR: print usage"; exit 1;;
esac
done
# users responsibility to reset OPTIND
OPTIND=1
}
parse_args -f xxx -c
parse_args -f yyy
Regular Expressions
Bash supports regular expression matching with the binary operator =~.
The match results can be accessed via the $BASH_REMATCH variable:
${BASH_REMATCH[0]}contains the full match${BASH_REMATCH[1]}contains match of the first capture group
INPUT='title foo : 1234'
REGEX='^title (.+) : ([0-9]+)$'
if [[ $INPUT =~ $REGEX ]]; then
echo "${BASH_REMATCH[0]}" # title foo : 1234
echo "${BASH_REMATCH[1]}" # foo
echo "${BASH_REMATCH[2]}" # 1234
fi
Caution: When specifying a
regexin the[[ ]]block directly, quotes will be treated as part of the pattern.[[ $INPUT =~ "foo" ]]will match against"foo"notfoo!
Completion
The complete builtin is used to interact with the completion system.
complete # print currently installed completion handler
complete -F <func> <cmd> # install <func> as completion handler for <cmd>
complete -r <cmd> # uninstall completion handler for <cmd>
Variables available in completion functions:
# in
$1 # <cmd>
$2 # current word
$3 # privous word
COMP_WORDS # array with current command line words
COMP_CWORD # index into COMP_WORDS with current cursor position
# out
COMPREPLY # array with possible completions
The compgen builtin is used to generate possible matches by comparing word
against words generated by option.
compgen <option> <word>
# usefule options:
# -W <list> specify list of possible completions
# -d generate list with dirs
# -f generate list with files
# -u generate list with users
# -e generate list with exported variables
# compare "f" against words "foo" "foobar" "bar" and generate matches
compgen -W "foo foobar bar" "f"
# compare "hom" against file/dir names and generate matches
compgen -d -f "hom"
Example
Skeleton to copy/paste for writing simple completions.
Assume a program foo with the following interface:
foo -c green|red|blue -s low|high -f <file> -h
The completion handler could be implemented as follows:
function _foo() {
local curr=$2
local prev=$3
local opts="-c -s -f -h"
case $prev in
-c) COMPREPLY=( $(compgen -W "green red blue" -- $curr) );;
-s) COMPREPLY=( $(compgen -W "low high" -- $curr) );;
-f) COMPREPLY=( $(compgen -f -- $curr) );;
*) COMPREPLY=( $(compgen -W "$opts" -- $curr) );;
esac
}
complete -F _foo foo
fish(1)
Quick Info
Fish initialization file ~/.config/fish/config.fish
Switch between different key bindings:
fish_default_key_bindingsto use default key bindingsfish_vi_key_bindingsto use vi key bindings
Variables
Available scopes
localvariable local to a blockglobalvariable global to shell instanceuniversalvariable universal to all shell instances + preserved across shell restart
Set/Unset Variables
set <name> [<values>]
-l local scope
-g global scope
-U universal scope
-e erase variable
-S show verbose info
-x export to ENV
-u unexport from ENV
Special Variables ref
$status # exit code of last command
$pipestatus # list of exit codes of pipe chain
$fish_pid # pid of parent fish shell ($$ in bash)
$last_pid # pid of last started process ($! in bash)
$CMD_DURATION # runtime of last command in ms
Lists
In fish all variables are lists (start with index 1, but lists can't
contain lists.
set foo a b c d
echo $foo[1] # a
echo $foo[-1] # d
echo $foo[2..3] # b c
echo $foo[1 3] # a c
$ can be seen as dereference operator.
set foo a; set a 1337
echo $$foo # outputs 1337
Cartesian product.
echo file.{h,cc}
# file.h file.cc
echo {a,b}{1,2}
# a1 b1 a2 b2
*PATH ref
Lists ending with PATH are automatically split at : when used and joined
with : when quoted or exported to the environment.
set -x BLA_PATH a:b:c:d
echo $BLA_PATH # a b c d
echo "$BLA_PATH" # a:b:c:d (quoted)
env | grep BLA_PATH # BLA_PATH=a:b:c:d (env)
set FOO_PATH x y z
echo $FOO_PATH # x y z
echo "$FOO_PATH" # x:y:z
Command Handling
# sub-commands are not run in quotes
echo "ls output: "(ls)
I/O redirection
# 'noclobber', fail if 'log' already exists
echo foo >? log
Process substitution
Redirect output of multiple processes. Same as <(..) in bash.
diff (sort a | psub) (sort b | psub)
Control Flow
if / else
if grep foo bar
# do sth
else if grep foobar bar
# do sth else
else
# do sth else
end
switch
switch (echo foo)
case 'foo*'
# do start with foo
case bar dudel
# do bar and dudel
case '*'
# do else
end
while Loop
while true
echo foo
end
for Loop
for f in (ls)
echo $f
end
Functions
Function arguments are passed via $argv list.
function fn_foo
echo $argv
end
Autoloading
When running a command fish attempts to autoload a function. The shell looks
for <cmd>.fish in the locations defined by $fish_function_path and loads
the function lazily if found.
This is the preferred way over monolithically defining all functions in a startup script.
Helper
functions # list al functions
functions foo # describe function 'foo'
functions -e foo # erase function 'foo'
funced foo # edit function 'foo'
# '-e vim' to edit in vim
Argument parsing and completion
argparse puts options into variables of name _flag_NAME.
References:
function moose --d "my moose fn"
# h/help : short / long option (boolean)
# color : only long option (boolean)
# u/user= : option with required argument, only last specified is taken
# f/file+= : option with required argument, can be specified multiple times
#
argparse h/help color= u/user= f/file=+ -- $argv
or return
if set -ql _flag_help
echo "usage ..."
return 0
end
set -ql _flag_file
and echo "file=$_flag_file | cnt:" (count $_flag_file)
set -ql _flag_color
and echo "color=$_flag_color"
set -ql _flag_user
and echo "user=$_flag_user"
end
# Delete all previous defined completions for 'moose'.
complete -c moose -e
# Don't complete files for command.
complete -c moose --no-files
# Help completion.
# -n specifies a conditions. The completion is only active if the command
# returns 0.
complete -c moose -s h -l help -n "not __fish_contains_opt -s h help" \
--description "Print usage help and exit"
# File completion.
# -F force complete files (overwrite --no-files).
# -r requires argument.
complete -c moose -s f -l file -F -r \
--description "Specify file (can be passed multiple times)"
# Color completion.
# -a options for completion.
# -x short for -r and --no-files (-f)
complete -c moose -x -l color -a "red blue" \
--description "Specify a color."
# User completion.
# -a options for completion. Call a function to generate arguments.
complete -c moose -x -s u -l user -a "(__fish_complete_users)" \
--description "Specify a user"
Prompt
The prompt is defined by the output of the fish_prompt function.
function fish_prompt
set -l cmd_ret
echo "> "(pwd) $cmd_ret" "
end
Use
set_colorto manipulate terminal colors andset_color -cto print the current colors.
Useful Builtins
List all builtins with builtins -n.
# history
history search <str> # search history for <str>
history merge # merge histories from fish sessions
# list
count $var # count elements in list
contains /bin $PATH # return 0 (true) 1 (false)
contains -i /bin $PATH # additionally print index on stdout
# string
string split SEP STRING
# math
math -b hex 4096 # output dec as hex
math 0x1000 # output hex as dec
math "log2(1024)" # call functions
math -s0 7/3 # integer division (by default float)
# status
status -f # abs path of current file
Keymaps
Shift-Tab .............. tab-completion with search
Alt-Up / Alt-Down ...... search history with token under the cursor
Alt-l .................. list content of dir under cursor
Alt-p .................. append '2>&1 | less;' to current cmdline
Alt-Left / Alt - Right . prevd / nextd, walk dir history
Debug
status print-stack-trace .. prints function stacktrace (can be used in scripts)
breakpoint ................ halt script execution and gives shell (C-d | exit
to continue)
CLI foo
awk(1)
awk [opt] program [input]
-F <sepstr> field separator string (can be regex)
program awk program
input file or stdin if not file given
Input processing
Input is processed in two stages:
- Splitting input into a sequence of
records. By default split atnewlinecharacter, but can be changed via the builtinRSvariable. - Splitting a
recordintofields. By default strings withoutwhitespace, but can be changed via the builtin variableFSor command line option-F.
Fields are accessed as follows:
$0wholerecord$1field one$2field two- ...
Program
An awk program is composed of pairs of the form:
pattern { action }
The program is run against each record in the input stream. If a pattern
matches a record the corresponding action is executed and can access the
fields.
INPUT
|
v
record ----> ∀ pattern matched
| |
v v
fields ----> run associated action
Any valid awk expr can be a pattern.
An example is the regex pattern /abc/ { print $1 } which prints the first
field if the record matches the regex /abc/. This form is actually a short
version for $0 ~ /abc/ { print $1 }, see the regex comparison operator
below.
Special pattern
awk provides two special patterns, BEGIN and END, which can be used
multiple times. Actions with those patterns are executed exactly once.
BEGINactions are run before processing the first recordENDactions are run after processing the last record
Special variables
RSrecord separator: first char is the record separator, by defaultFSfield separator: regex to split records into fields, by defaultNRnumber record: number of current recordNFnumber fields: number of fields in the current record
Special statements & functions
-
printf "fmt", args...Print format string, args are comma separated.
%sstring%ddecimal%xhex%ffloat
Width can be specified as
%Ns, this reservesNchars for a string. For floats one can use%N.Mf,Nis the total number including.andM. -
sprintf("fmt", expr, ...)Format the expressions according to the format string. Similar as
printf, but this is a function and return value can be assigned to a variable. -
strftime("fmt")Print time stamp formatted by
fmt.%Yfull year (eg 2020)%mmonth (01-12)%dday (01-31)%Falias for%Y-%m-%d%Hhour (00-23)%Mminute (00-59)%Ssecond (00-59)%Talias for%H:%M:%S
-
S ~ R,S !~ RThe regex comparison operator, where the former returns true if the string
Smatches the regexR, and the latter is the negated form. The regex can be either a constant or dynamic regex.
Examples
Filter records
awk 'NR%2 == 0 { print $0 }' <file>
The pattern NR%2 == 0 matches every second record and the action { print $0 }
prints the whole record.
Negative patterns
awk '!/^#/ { print $1 }' <file>
Matches records not starting with #.
Range patterns
echo -e "a\nFOO\nb\nc\nBAR\nd" | \
awk '/FOO/,/BAR/ { print }'
/FOO/,/BAR/ define a range pattern of begin_pattern, end_pattern. When
begin_pattern is matched the range is turned on and when the
end_pattern is matched the range is turned off. This matches every record
in the range inclusive.
An exclusive range must be handled explicitly, for example as follows.
echo -e "a\nFOO\nb\nc\nBAR\nd" | \
awk '/FOO/,/BAR/ { if (!($1 ~ "FOO") && !($1 ~ "BAR")) { print } }'
Access last fields in records
echo 'a b c d e f' | awk '{ print $NF $(NF-1) }'
Access last fields with arithmetic on the NF number of fields variable.
Split on multiple tokens
echo 'a,b;c:d' | awk -F'[,;:]' '{ printf "1=%s | 4=%s\n", $1, $4 }'
Use regex as field separator.
Capture in variables
# /proc/<pid>/status
# Name: cat
# ...
# VmRSS: 516 kB
# ...
for f in /proc/*/status; do
cat $f | awk '
/^VmRSS/ { rss = $2/1024 }
/^Name/ { name = $2 }
END { printf "%16s %6d MB\n", name, rss }';
done | sort -k2 -n
We capture values from VmRSS and Name into variables and print them at the
END once processing all records is done.
Capture in array
echo 'a 10
b 2
b 4
a 1' | awk '{
vals[$1] += $2
cnts[$1] += 1
}
END {
for (v in vals)
printf "%s %d\n", v, vals[v] / cnts [v]
}'
Capture keys and values from different columns and some up the values.
At the END we compute the average of each key.
Run shell command and capture output
cat /proc/1/status | awk '
/^Pid/ {
"ps --no-header -o user " $2 | getline user;
print user
}'
We build a ps command line and capture the first line of the processes output
in the user variable and then print it.
cut(1)
# Remove sections from each line of files(s).
cut OPT FILE [FILE]
-d DELIM delimiter to tokenize
-f LIST field selector
-c LIST character selector
Example: only selected characters
echo 'aa bb cc dd' | cut -c "1-4"
# aa b
# Inverted selection.
echo 'aa bb cc dd' | cut --complement -c "1-4"
# b cc dd
Example: only selected fields
Fields in cut are indexed starting from 1 rather than 0.
# Fields 2 until 3.
echo 'aa bb cc dd' | cut -d ' ' -f 2-3
# bb cc
# First field until the 2nd.
echo 'aa bb cc dd' | cut -d ' ' -f -2
# aa bb
# Third field until the end.
echo 'aa bb cc dd' | cut -d ' ' -f 3-
# cc dd
# If the number of tokens in a line is unkown but we want to remove the last 2
# tokens we can use rev(1).
echo 'aa bb cc dd' | rev | cut -d ' ' -f3- | rev
# aa bb
sed(1)
sed [opts] [script] [file]
opts:
-i edit file in place
-i.bk edit file in place and create backup file
(with .bk suffix, can be specified differently)
--follow-symlinks
follow symlinks when editing in place
-e SCRIPT add SCRIPT to commands to be executed
(can be specified multiple times)
-f FILE add content of FILE to command to be executed
--debug annotate program execution
Examples
Delete lines
# Delete two lines.
echo -e 'aa\nbb\ncc\ndd' | sed '1d;3d'
# bb
# dd
# Delete last ($) line.
echo -e 'aa\nbb\ncc\ndd' | sed '$d'
# aa
# bb
# cc
# Delete range of lines.
echo -e 'aa\nbb\ncc\ndd' | sed '1,3d'
# dd
# Delete lines matching pattern.
echo -e 'aa\nbb\ncc\ndd' | sed '/bb/d'
# aa
# cc
# dd
# Delete lines NOT matching pattern.
echo -e 'aa\nbb\ncc\ndd' | sed '/bb/!d'
# bb
Insert lines
# Insert before line.
echo -e 'aa\nbb' | sed '2iABC'
# aa
# ABC
# bb
# Insert after line.
echo -e 'aa\nbb' | sed '2aABC'
# aa
# bb
# ABC
# Replace line.
echo -e 'aa\nbb' | sed '2cABC'
# aa
# ABC
# Insert before pattern match.
echo -e 'aa\nbb' | sed '/bb/i 123'
# aa
# 123
# bb
Substitute lines
# Substitute by regex.
echo -e 'aafooaa\ncc' | sed 's/foo/MOOSE/'
# aaMOOSEaa
# cc
Multiple scripts
echo -e 'foo\nbar' | sed -e 's/foo/FOO/' -e 's/FOO/BAR/'
# BAR
# bar
Edit inplace through symlink
touch file
ln -s file link
ls -l link
# lrwxrwxrwx 1 johannst johannst 4 Feb 7 23:02 link -> file
sed -i --follow-symlinks '1iabc' link
ls -l link
# lrwxrwxrwx 1 johannst johannst 4 Feb 7 23:02 link -> file
sed -i '1iabc' link
ls -l link
# -rw-r--r-- 1 johannst johannst 0 Feb 7 23:02 link
column(1)
Examples
# Show as table (aligned columns), with comma as delimiter from stdin.
echo -e 'a,b,c\n111,22222,33' | column -t -s ','
# Show file as table.
column -t -s ',' test.csv
sort(1)
sort [opts] [file]
opts:
-r reverse output
-b ignore leading blanks
-n sort by numeric
-h sort by human numeric
-V sort by version
-k<N> sort by Nth key
-t<S> field separator
Examples
# Sort by directory sizes.
du -sh * | sort -h
# Sort numeric by second key.
# The default key separator is non-blank to blank transition.
echo 'a 4
d 10
c 21' | sort -k2 -n
# Sort numeric by second key, split at comma.
echo 'a,4
d,10
c,21' | sort -k2 -n -t,
Use
--debugto annotate part of the line used to sort and hence debug the key usage.
tr(1)
tr [opt] str1 [str2]
-d delete characters in str1
-s squeeze repeating sequence of characters in str1
Examples
To lower
echo MoOsE | tr '[:upper:]' '[:lower:]'
# output: moose
Replace characters
echo moose | tr 'o' '-'
# output: m--se
echo moose | tr 'os' '-'
# output: m---e
Remove specific characters
echo moose | tr -d 'o'
# output: mse
echo moose | tr -d 'os'
# output: me
Squeeze character sequences
echo moooooossse | tr -s 'os'
# output: mose
tac(1)
# Reverse output lines of file(s) and concatenate (reverse of cat).
tac FILE [FILE]
echo -e 'a1\nb2\nc3\nd4' | tac
# d4
# c3
# b2
# a1
rev(1)
# Reverse each line of file(s), character by character.
rev FILE [FILE]
echo -e '123\nabc' | rev
# 321
# cba
Example: remove the last 2 tokens with unknown length
# If the number of tokens in a line is unkown but we want to remove the last 2
# tokens we can use rev(1).
echo 'aa bb cc dd' | rev | cut -d ' ' -f3- | rev
# aa bb
paste(1)
# Concatenate input files linewise and join them by a TAB char.
paste FILE [FILE]
-d CHAR delimiter to join each line
Examples
# Read two files.
paste <(echo -e 'a1\na2') <(echo -e 'b1\nb2')
a1 b1
a2 b2
# Can read from stdin.
echo -e 'a1 a2\nb1 b2\nc1 c2\nd1 d2' | paste - -
# a1 a2 b1 b2
# c1 c2 d1 d2
xargs(1)
xargs [opts] [cmd [init-args]]
-l [<num>] maximal number of lines per cmd invocation
if <num> it not provided, num=1 is assumed
-I <str> replace <str> in the [init-args] with the arg;
this implies -l, and hence processes one arg at a time
Example
Collect arguments and prefix them with another option.
# Using -l to process one arg at a time.
eval strace -f (find /dev -name 'std*' | xargs -l echo -P | xargs) ls
# Using -I to place the arg at the specified location.
eval strace -f (find /dev -name 'std*' | xargs -I {} echo -P {}) ls
# Both commands achieve the same thing and result in something like:
# eval strace -f -P /dev/stdin -P /dev/stdout -P /dev/stderr ls
grep(1)
grep [opts] [pattern] [files]
-e <pattern> pattern to search for (can be supplied multiple times)
-i ignore case in patterns
-v invert match
-n add line numbers to matched lines
-H add file name to matched lines
-r recursively read all files
-I skip binary files
--include <glob> search only files matching glob
--exclude <glob> skip searching files matching glob
-c count occurrence of matched patterns
-l list only file name which contain the pattern
<glob>patterns may need to be quoted or escaped if the shell also does glob expansion.
find(1)
find <start> [opts]
-maxdepth <n> maximally search n dirs deep
-type <t> match on file type
f regular file
d directory
-user <name> list files owned by username
-name <glob> list files matching glob (only filename)
-iname <glob> list files matching glob case-insensitive
-exec <cmd> {} ; run cmd on each file
-exec <cmd> {} + run cmd with all files as argument
Depending on the shell the
<glob>must be quoted or escaped. The exec modifier characters;and+also may need to be escaped.
Example -exec option
> find . -maxdepth 1 -type d -exec echo x {} \;
# x .
# x ./.github
# x ./book
# x ./src
# x ./.git
# x ./docs
> find . -maxdepth 1 -type d -exec echo x {} +
# x . ./.github ./book ./src ./.git ./docs
dd(1)
Copy data block-wise.
dd [opts]
if=<path> input file to read (stdin in case not specified)
of=<path> oputput file to write
status=progress show progress while copying
bs=<bytes> block size
count=<n> copy only <n> blocks
skip=<n> skip <n> blocks in input (seek input)
seek=<n> skip <n> blocks in oputput (seek output)
conv=<conv>
notrunc dont truncate output file
excl fail if output already exists
nocreat fail if output does not exists
Example: bootstick
dd bs=4M if=<iso> of=<blkdev> oflag=sync status=progress
Example: patch file in place
# Create a 1024 bytes file filled with zeros.
dd if=/dev/zero of=disk bs=512 count=2
# Overwrite 4 bytes starting at byte 0.
printf "aaaa" | dd of=disk bs=1 seek=0 conv=notrunc
# Overwrite 4 bytes starting at byte 512.
printf "bbbb" | dd of=disk bs=1 seek=512 conv=notrunc
hexdump disk
# 0000000 6161 6161 0000 0000 0000 0000 0000 0000
# 0000010 0000 0000 0000 0000 0000 0000 0000 0000
# *
# 0000200 6262 6262 0000 0000 0000 0000 0000 0000
# 0000210 0000 0000 0000 0000 0000 0000 0000 0000
# *
# 0000400
Tools
tmux(1)
Terminology:
sessionis a collection of pseudo terminals which can have multiplewindowswindowuses the entire screen and can be split into rectangularpanespaneis a single pseudo terminal instance
Tmux cli
# Session
tmux creates new session
tmux ls list running sessions
tmux kill-session -t <s> kill running session <s>
tmux attach -t <s> [-d] attach to session <s>, detach other clients [-d]
tmux detach -s <s> detach all clients from session <s>
# Environment
tmux showenv -g show global tmux environment variables
tmux setenv -g <var> <val> set variable in global tmux env
# Misc
tmux source-file <file> source config <file>
tmux lscm list available tmux commnds
tmux show -g show global tmux options
tmux display <msg> display message in tmux status line
Scripting
# Session
tmux list-sessions -F '#S' list running sessions, only IDs
# Window
tmux list-windows -F '#I' -t <s> list window IDs for session <s>
tmux selectw -t <s>:<w> select window <w> in session <s>
# Pane
tmux list-panes -F '#P' -t <s>:<w> list pane IDs for window <w> in session <s>
tmux selectp -t <s>:<w>.<p> select pane <p> in window <w> in session <s>
# Run commands
tmux send -t <s>:<w>.<p> "ls" C-m send cmds/keys to pane
tmux run -t <p> <sh-cmd> run shell command <sh-cmd> in background and report output on pane -t <p>
For example cycle through all panes in all windows in all sessions:
# bash
for s in $(tmux list-sessions -F '#S'); do
for w in $(tmux list-windows -F '#I' -t $s); do
for p in $(tmux list-panes -F '#P' -t $s:$w); do
echo $s:$w.$p
done
done
done
Bindings
prefix d detach from current session
prefix c create new window
prefix w open window list
prefix $ rename session
prefix , rename window
prefix . move current window
Following bindings are specific to my tmux.conf:
C-s prefix
# Panes
prefix s horizontal split
prefix v vertical split
prefix f toggle maximize/minimize current pane
# Movement
prefix Tab toggle between window
prefix h move to pane left
prefix j move to pane down
prefix k move to pane up
prefix l move to pane right
# Resize
prefix C-h resize pane left
prefix C-j resize pane down
prefix C-k resize pane up
prefix C-l resize pane right
# Copy/Paste
prefix C-v enter copy mode
prefix C-p paste yanked text
prefix C-b open copy-buffer list
# In Copy Mode
v enable visual mode
y yank selected text
Command mode
To enter command mode prefix :.
Some useful commands are:
setw synchronize-panes on/off enables/disables synchronized input to all panes
list-keys -t vi-copy list keymaps for vi-copy mode
screen(1)
# Create new session.
screen
# List active session.
screen -list
# Attach to specific session.
screen -r SESSION
Options
# Enable logfile, default name screenlog.0.
screen -L
# Enable log and set logfile name.
screen -L -Logfile out.txt
Keymaps
Ctrl-A d # Detach from session.
Ctrl-A + \ # Terminate session.
Ctrl-A + : # Open cmand prompt.
kill # Kill session.
Examples
USB serial console.
# 1500000 -> baudrate
# cs8 -> 8 data bits
# -cstopb -> 1 stop bit
# -parenb -> no parity bit
# see stty(1) for all settings.
screen /dev/ttyUSB0 1500000,cs8,-cstopb,-parenb
# Print current tty settings.
sudo stty -F /dev/ttyUSB0 -a
emacs(1)
help
C-h ? list available help modes
C-h e show message output (`*Messages*` buffer)
C-h f describe function
C-h v describe variable
C-h w describe which key invoke function (where-is)
C-h c <KEY> print command bound to <KEY>
C-h k <KEY> describe command bound to <KEY>
C-h b list buffer local key-bindings
C-h F show emacs manual for command/function
<kseq> C-h list possible key-bindings with <kseq>
eg C-x C-h -> list key-bindings beginning with C-x
package manager
key fn description
------------------------------------------------
package-refresh-contents refresh package list
package-list-packages list available/installed packages
`U x` to mark packages for Upgrade & eXecute
window
key fn description
----------------------------------------------
C-x 0 delete-window kill focused window
C-x 1 delete-other-windows kill all other windows
C-x 2 split-window-below split horizontal
C-x 3 split-window-right split vertical
C-x o other-window other window (cycle)
C-x r w window-configuration-to-register
save window configuration in a register
(use C-x r j to jump to the windows config again)
minibuffer
key description
----------------------------
M-e enter edit minibuffer edit mode
M-up focus previous completion
M-down focus next completion
M-ret select focused completion
buffer
key fn description
---------------------------------------------
C-x C-q read-only-mode toggle read-only mode for buffer
C-x k kill-buffer kill buffer
C-x s save-some-buffers save buffer
C-x w write-file write buffer (save as)
C-x b switch-to-buffer switch buffer
C-x C-b list-buffers buffer list
C-x x r rename-buffer renames a buffer (allows multiple shell, compile, grep, .. buffers)
ibuffer
Builtin advanced buffer selection mode
key fn description
--------------------------------------
ibuffer enter buffer selection
h ibuffer help
d mark for deletion
x kill buffers marked for deletion
o open buffer in other window
C-o open buffer in other window keep focus in ibuffer
s a sort by buffer name
s f sort by file name
s v sort by last viewed
s v sort by major mode
, cycle sorting mode
= compare buffer against file on disk (if file is dirty `*`)
/m filter by major mode
/n filter by buffer name
/f filter by file name
/i filter by modified buffers
/E filter by process buffers
// remove all filter
/g create filter group
/\ remove all filter groups
goto navigation
key fn description
----------------------------------------
M-g g goto-line go to line
M-g M-n next-error go to next error (grep, xref, compilation, ...)
M-g M-p previous-error go to previous error
M-g i imenu go to place in buffer (symbol, ...)
M-< go to begin of buffer
M-> go to end of buffer
isearch
key fn description
-------------------------------------------------
C-s isearch-forward search forward from current position (C-s to go to next match)
C-r isearch-backward search backwards from current position (C-r to go to next match)
C-w isearch-yank-word-or-char feed next word to current search (extend)
M-p isearch-ring-advance previous search input
M-n isearch-ring-retreat next search input
M-e isearch-edit-string edit search string again
M-s o occur open search string in occur
occur
key fn description
-----------------------------------
M-s o occur get matches for regexp in buffer
use during `isearch` to use current search term
e enter occur edit mode (C-c C-c to quit)
n move to next entry and keep focus in occur buffer
p move to previous entry and keep focus in occur buffer
C-n goto next line
C-p goto previous line
o open match in other window
C-o open match in other window keep focus in ibuffer
key fn description
---------------------------------------------------------
multi-occur-in-matching-buffers run occur in buffers matching regexp
grep
key fn description
-----------------------------------
rgrep recursive grep
lgrep local dir grep
grep raw grep command
find-grep run find-grep result in *grep* buffer
n/p navigate next/previous match in *grep* buffer
q quit *grep* buffer
yank/paste
key fn description
-------------------------------------------------
C-<SPACE> set-mark-command set start mark to select text
C-x C-x exchange-point-and-mark swap mark and point position
M-w kill-ring-save copy selected text
C-w kill-region kill selected text
C-y yank paste selected text
M-y yank-pop cycle through kill-ring (only after paste)
M-y yank-from-kill-ring interactively select yank from kill ring
register
key fn description
------------------------------------------------
C-x r s <reg> copy-to-register save region in register <reg>
C-x r i <reg> insert-register insert content of register <reg>
bookmarks
key fn description
-------------------------------------------
C-x r m bookmark-set set a bookmark
C-x r b bookmark-jump jump to a bookmark
C-x r l bookmark-bmenu-list list all bookmarks
block/rect
key fn description
------------------------------------------------
C-x <SPC> rectangle-mark-mode activate rectangle-mark-mode
string-rectangle insert text in marked rect
mass edit
key fn description
------------------------------------------------
C-x h mark-whole-buffer mark whole buffer
delete-matching-line delete lines matchng regex
kill-matching-line kill lines matching regex (puts them in kill ring)
keep-lines keep matching lines
replace-string replace unconditional
M-% query-replace search & replace
C-M-% query-replace-regexp search & replace regex
narrow
key fn description
---------------------------------------------
C-x n n narrow-to-region show only focused region (narrow)
C-x n w widen show whole buffer (wide)
org
key fn description
------------------------------------
M-up/M-down re-arrange items in same hierarchy
M-left/M-right change item hierarchy
C-RET create new item below current
C-S-RET create new TODO item below current
S-left/S-right cycle TODO states
org source
key fn description
------------------------------
<s TAB generate a source block
C-c ' edit source block (in lang specific buffer)
C-c C-c eval source block
project
key fn description
----------------------------------------------------------
C-x p p project-switch-project switch project
C-x p f project-find-file find file in project
C-x p r project-query-replace-regexp query replace on project
C-x p x project-execute-extended-command exec command on project
C-x p ! project-shell-command shell command on project
C-x p & project-async-shell-command async shell command on project
tags / lsp
To generate etags using ctags
ctags -R -e . generate emacs tag file (important `-e`)
Navigate using tags
key fn description
-----------------------------------------------
M-. xref-find-definitions find definition of tag
(C-u prefix to enter symbol manually)
xref-find-apropos find symbols matching regexp
M-? xref-find-references find references of tag
lisp
key fn description
------------------------------
ielm open interactive elips shell
In lisp-interaction-mode (*scratch* buffer by defult)
key fn description
-----------------------------------------------------------
C-j eval-print-last-sexp evaluate & print preceeding lisp expr
C-x C-e eval-last-sexp evaluate lisp expr
C-u C-x C-e eval-last-sexp evaluate & print
C-c C-e elisp-eval-region-or-buffer eval buffer or region (elisp mode)
ido
Builtin fuzzy completion mode (eg buffer select, dired, ...).
key fn description
------------------------------------------
ido-mode toggle ido mode
<Left>/<Right> cycle through available competions
<RET> select completion
There is also fido, which is the successor of ido, which also
supports fido-vertical-mode in case vertical mode is preferred.
evil
key fn description
--------------------------
C-z toggle emacs/evil mode
C-^ toggle between previous and current buffer
C-p after paste cycle kill-ring back
C-n after paste cycle kill-ring forward
dired
key fn description
--------------------------
i open sub-dir in same buffer
+ create new directory
C copy file/dir
R move file/dir (rename)
S absolute symbolic link
Y relative symbolic link
d mark for deletion
m mark file/dir at point
* % mark by regex
* * mark all executables
* / mark all dirs
u un-mark file/dir
U un-mark all
t toggle marks
x execute marked actions
! run shell command on marked files
& run shell command on marked files (async)
q quit
info
key fn description
---------------------------------------
n Info-next next page
p Info-prev previous page
l Info-history-back history go back
r Info-history-forward history go forward
^ Info-Up up in info node tree
m Info-menu goto menu (by minibuf completion)
s Info-search search info
g Info-goto-node goto info node (by minibuf completion)
Info-history open info history in buffer
shell commands
key fn description
---------------------------------------------
M-! shell-command run shell command synchronously
M-& async-shell-command run shell command asynchronously
M-| shell-command-on-region run shell command on region;
prefix with C-u to replace region with
output of the command
interactive shell
Set ESHELL environment variable before starting emacs to change
default shell, else customize the explicit-shell-file-name variable.
key fn description
---------------------------------------------
M-x shell start interactive shell
C-u M-x shell start interactive shell & rename
M-r comint-history-isearch-backward-regexp
search history, invoke at end of shell buffer
M-p comint-previous-input go one up in history
C-<UP>
M-n comint-next-input go one down in history
C-<DOWN>
C-c C-a go begin of line (honors prompt)
C-c C-e go to end of line
C-c C-c interrupt active command
gpg(1)
gpg
-o|--output Specify output file
-a|--armor Create ascii output
-u|--local-user <name> Specify key for signing
-r|--recipient Encrypt for user
Generate new keypair
gpg --full-generate-key
List keys
gpg -k / --list-key # public keys
gpg -K / --list-secret-keys # secret keys
Edit keys
gpg --edit-key <KEY ID>
Gives prompt to modify KEY ID, common commands:
help show help
save save & quit
list list keys and user IDs
key <N> select subkey <N>
uid <N> select user ID <N>
expire change expiration of selected key
adduid add user ID
deluid delete selected user ID
addkey add subkey
delkey delete selected subkey
Export & Import Keys
gpg --export --armor --output <KEY.PUB> <KEY ID>
gpg --export-secret-key --armor --output <KEY.PRIVATE> <KEY ID>
gpg --import <FILE>
Search & Send keys
gpg --keyserver <SERVER> --send-keys <KEY ID>
gpg --keyserver <SERVER> --search-keys <KEY ID>
Encrypt (passphrase)
Encrypt file using passphrase and write encrypted data to <file>.gpg.
gpg --symmetric <file>
# Decrypt using passphrase
gpg -o <file> --decrypt <file>.gpg
Encrypt (public key)
Encrypt file with public key of specified recipient and write encrypted
data to <file>.gpg.
gpg --encrypt -r foo@bar.de <file>
# Decrypt at foos side (private key required)
gpg -o <file> --decrypt <file>.gpg
Signing
Generate a signed file and write to <file>.gpg.
# Sign with private key of foo@bar.de
gpg --sign -u foor@bar.de <file>
# Verify with public key of foo@bar.de
gpg --verify <file>
# Extract content from signed file
gpg -o <file> --decrypt <file>.gpg
Without
-uuse first private key in listgpg -Kfor signing.
Files can also be signed and encrypted at once, gpg will first sign the
file and then encrypt it.
gpg --sign --encrypt -r <recipient> <file>
Signing (detached)
Generate a detached signature and write to <file>.asc.
Send <file>.asc along with <file> when distributing.
gpg --detach-sign --armor -u foor@bar.de <file>
# Verify
gpg --verify <file>.asc <file>
Without
-uuse first private key in listgpg -Kfor signing.
Abbreviations
secsecret keyssbsecret subkeypubpublic keysubpublic subkey
Key usage flags:
[S]signing[C]create certificates[E]encrypting[A]authentication
Keyservers
- http://pgp.mit.edu
- http://keyserver.ubuntu.com
- hkps://pgp.mailbox.org
Examples
List basic key information from file with long keyids
gpg --keyid-format 0xlong <key.asc>
Extend expiring key
gpg --edit-key <key id>
# By default we are on the primary key, can switch to sub key.
gpg> key 1
# Update the expire date.
gpg> expire
gpg> save
# Update keyserver(s) and/or export new pub keyfile.
radare2(1)
pd <n> [@ <addr>] # print disassembly for <n> instructions
# with optional temporary seek to <addr>
flags
fs # list flag-spaces
fs <fs> # select flag-space <fs>
f # print flags of selected flag-space
help
?*~<kw> # '?*' list all commands and '~' grep for <kw>
?*~... # '..' less mode /'...' interactive search
relocation
> r2 -B <baddr> <exe> # open <exe> mapped to addr <baddr>
oob <addr> # reopen current file at <baddr>
Examples
Patch file (alter bytes)
> r2 [-w] <file>
oo+ # re-open for write if -w was not passed
s <addr> # seek to position
wv <data> # write 4 byte (dword)
Assemble / Disassmble (rasm2)
rasm2 -L # list supported archs
> rasm2 -a x86 'mov eax, 0xdeadbeef'
b8efbeadde
> rasm2 -a x86 -d "b8efbeadde"
mov eax, 0xdeadbeef
qemu(1)
All the examples & notes use qemu-system-x86_64 but in most cases
this can be swapped with the system emulator for other architectures.
Keybindings
Graphic mode:
Ctrl+Alt+g release mouse capture from VM
Ctrl+Alt+1 switch to display of VM
Ctrl+Alt+2 switch to qemu monitor
No graphic mode:
Ctrl+a h print help
Ctrl+a x exit emulator
Ctrl+a c switch between monitor and console
VM config snippet
Following command-line gives a good starting point to assemble a VM:
qemu-system-x86_64 \
-cpu host -enable-kvm -smp 4 \
-m 8G \
-vga virtio -display sdl,gl=on \
-boot menu=on \
-cdrom <iso> \
-hda <disk> \
-device qemu-xhci,id=xhci \
-device usb-host,bus=xhci.0,vendorid=0x05e1,productid=0x0408,id=capture-card
CPU & RAM
# Emulate host CPU in guest VM, enabling all supported host featured (requires KVM).
# List available CPUs `qemu-system-x86_64 -cpu help`.
-cpu host
# Enable KVM instead software emulation.
-enable-kvm
# Configure number of guest CPUs.
-smp <N>
# Configure size of guest RAM.
-m 8G
Graphic & Display
# Use sdl window as display and enable openGL context.
-display sdl,gl=on
# Use vnc server as display (eg on display `:42` here).
-display vnc=localhost:42
# Confifure virtio as 3D video graphic accelerator (requires virgl in guest).
-vga virtio
# Disable graphical output, and redirect serial console to qemu processes stdio
# (-serial stdio).
-nographic
Boot Menu
# Enables boot menu to select boot device (enter with `ESC`).
-boot menu=on
Block devices
# Attach cdrom drive with iso to a VM.
-cdrom <iso>
# Attach disk drive to a VM.
-hda <disk>
# Generic way to configure & attach a drive to a VM.
-drive file=<file>,format=qcow2
Create a disk with qemu-img
To create a qcow2 disk (qemu copy-on-write) of size 10G:
qemu-img create -f qcow2 disk.qcow2 10G
The disk does not contain any partitions or a partition table.
We can format the disk from within the guest as following example:
# Create `gpt` partition table.
sudo parted /dev/sda mktable gpt
# Create two equally sized primary partitions.
sudo parted /dev/sda mkpart primary 0% 50%
sudo parted /dev/sda mkpart primary 50% 100%
# Create filesystem on each partition.
sudo mkfs.ext3 /dev/sda1
sudo mkfs.ext4 /dev/sda2
lsblk -f /dev/sda
NAME FSTYPE LABEL UUID FSAVAIL FSUSE% MOUNTPOINT
sda
├─sda1 ext3 ....
└─sda2 ext4 ....
USB
Host Controller
# Add XHCI USB controller to the VM (supports USB 3.0, 2.0, 1.1).
# `id=xhci` creates a usb bus named `xhci`.
-device qemu-xhci,id=xhci
USB Device
# Pass-through USB device from host identified by vendorid & productid and
# attach to usb bus `xhci.0` (defined with controller `id`).
-device usb-host,bus=xhci.0,vendorid=0x05e1,productid=0x0408
Debugging
# Open gdbstub on tcp `<port>` (`-s` shorthand for `-gdb tcp::1234`).
-gdb tcp::<port>
# Freeze guest CPU at startup and wait for debugger connection.
-S
IO redirection
# Create raw tcp server for `serial IO` and wait until a client connects
# before executing the guest.
-serial tcp:localhost:12345,server,wait
# Create telnet server for `serial IO` and wait until a client connects
# before executing the guest.
-serial telnet:localhost:12345,server,wait
# Configure redirection for the QEMU `mointor`, arguments similar to `-serial`
# above.
-monitor ...
In
servermode usenowaitto execute guest without waiting for a client connection.
Network
# Redirect host tcp port `1234` to guest port `4321`.
-nic user,hostfwd=tcp:localhost:1234-:4321
Shared drives
# Attach a `virtio-9p-pci` device to the VM.
# The guest requires 9p support and can mount the shared drive as:
# mount -t 9p -o trans=virtio someName /mnt
-virtfs local,id=someName,path=<someHostPath>,mount_tag=someName,security_model=none
Debug logging
# List debug items.
-d help
# Write debug log to file instead stderr.
-D <file>
# Examples
-d in_asm Log executed guest instructions.
Tracing
# List name of all trace points.
-trace help
# Enable trace points matching pattern and optionally write trace to file.
-trace <pattern>[,file=<file>]
# Enable trace points for all events listed in the <events> file.
# File must contain one event/pattern per line.
-trace events=<events>
VM snapshots
VM snapshots require that there is at least on qcow2 disk attached to the VM
(VM Snapshots).
Commands for qemu Monitor or QMP:
# List available snapshots.
info snapshots
# Create/Load/Delete snapshot with name <tag>.
savevm <tag>
loadvm <tag>
delvm <tag>
The snapshot can also be directly specified when invoking qemu as:
qemu-system-x86_64 \
-loadvm <tag> \
...
VM Migration
Online migration example:
# Start machine 1 on host ABC.
qemu-system-x86_64 -monitor stdio -cdrom <iso>
# Prepare machine 2 on host DEF as migration target.
# Listen for any connection on port 12345.
qemu-system-x86_64 -monitor stdio -incoming tcp:0.0.0.0:12345
# Start migration from the machine 1 monitor console.
(qemu) migrate tcp:DEF:12345
Save to external file example:
```bash
# Start machine 1.
qemu-system-x86_64 -monitor stdio -cdrom <iso>
# Save VM state to file.
(qemu) migrate "exec:gzip -c > vm.gz"
# Load VM from file.
qemu-system-x86_64 -monitor stdio -incoming "exec: gzip -d -c vm.gz"
The migration source machine and the migration target machine should be launched with the same parameters.
Appendix: Direct Kernel boot
Example command line to directly boot a Kernel with an initrd ramdisk.
qemu-system-x86_64 \
-cpu host \
-enable-kvm \
-kernel <dir>/arch/x86/boot/bzImage \
-append "earlyprintk=ttyS0 console=ttyS0 nokaslr init=/init debug" \
-initrd <dir>/initramfs.cpio.gz \
...
Instructions to build a minimal Kernel and initrd.
Appendix: Cheap instruction tracer
test: test.s
as -o test.o test.s
ld -o test test.o testc.o
trace: test
qemu-x86_64 -singlestep -d nochain,cpu ./test 2>&1 | awk '/RIP/ { print $$1; }'
clean:
$(RM) test test-bin test.o
.section .text, "ax"
.global _start
_start:
xor %rax, %rax
mov $0x8, %rax
1:
cmp $0, %rax
je 2f
dec %rax
jmp 1b
2:
# x86-64 exit(2) syscall
mov $0, %rdi
mov $60, %rax
syscall
References
- QEMU USB
- QEMU IMG
- QEMU Tools
- QEMU System
- QEMU Invocation (command line args)
- QEMU Monitor
- QEMU machine protocol (QMP)
- QEMU VM Snapshots
pacman(1)
Remote package repositories
pacman -Sy refresh package database
pacman -S <pkg> install pkg
pacman -Ss <regex> search remote package database
pacman -Si <pkg> get info for pkg
pacman -Su upgrade installed packages
pacman -Sc clean local package cache
Remove packages
pacman -Rsn <pkg> uninstall package and unneeded deps + config files
Local package database
Local package database of installed packages.
pacman -Q list all installed packages
pacman -Qs <regex> search local package database
pacman -Ql <pkg> list files installed by pkg
pacman -Qo <file> query package that owns file
pacman -Qe only list explicitly installed packages
Local file database
Local file database which allows to search packages owning certain files. Also searches non installed packages, but database must be synced.
pacman -Fy refresh file database
pacman -Fl <pkg> list files in pkg (must not be installed)
pacman -Fx <regex> search
Hacks
Uninstall all orphaned packages (including config files) that were installed as dependencies.
pacman -Rsn $(pacman -Qtdq)
List explicitly installed packages that are not required as dependency by any package and sort by size.
pacman -Qetq | xargs pacman -Qi |
awk '/Name/ { name=$3 }
/Installed Size/ { printf "%8.2f%s %s\n", $4, $5, name }' |
sort -h
Install package into different root directory but keep using the default
database.
pacman --root abc --dbpath /var/lib/pacman -S mingw-w64-gcc
dot(1)
Example dot file to copy & paste from.
Can be rendered to svg with the following command.
dot -T svg -o g.svg g.dot
Example dot file.
// file: g.dot
digraph {
// Render ranks from left to right.
rankdir=LR
// Make background transparent.
bgcolor=transparent
// Global node attributes.
node [shape=box]
// Global edge attributes.
edge [style=dotted,color=red]
// Add nodes & edge.
stage1 -> stage2
// Add multiple edges at once.
stage2 -> { stage3_1, stage3_2 }
// Add edge with custom attributes.
stage3_2 -> stage4 [label="some text"]
// Set custom attributes for specific node.
stage4 [color=green,fillcolor=lightgray,style="filled,dashed",label="s4"]
// Create a subgraph. This can be used to group nodes/edges or as scope for
// global node/edge attributes.
// If the name starts with 'cluster' a border is drawn.
subgraph cluster_1 {
stage5_1
stage5_2
}
// Add some edges to subgraph nodes.
stage3_1 -> { stage5_1, stage5_2 }
}
Rendered svg file.

References
ffmpeg (1)
screen capture specific window (x11)
Following snippet allows to select a window which is then captured.
#!/bin/bash
echo "Click on window to record .."
# Extract window size and x,y offset.
video_args=$(xwininfo \
| awk '/Absolute upper-left X:/ { xoff = $4 }
/Absolute upper-left Y:/ { yoff=$4 }
/Width:/ { if ($2 % 2 == 1) { width=$2-1; } else { width=$2; } }
/Height:/ { if ($2 % 2 == 1) { height=$2-1; } else { height=$2; } }
END { printf "-video_size %dx%d -i :0.0+%d,%d", width, height, xoff, yoff }')
ffmpeg -framerate 25 -f x11grab $video_args -pix_fmt yuv420p $@ output.mp4
Use
yuv420ppixel format if video is played on the web (ref)
The input -i 0,0+xoff,yoff means to capture $DISPLAY=0.0 starting at the
coordinate (xoff, yoff), which is the left-upper corner, and the size of the
capture is defined by the -video_size argument.
gnuplot (1)
# Launch interactive shell.
gnuplot
# Launch interactive shell.
gnuplot [opt]
opt:
-p ................ persist plot window
-c <file> ......... run script file
-e "<cmd1>; .." ... run cmd(s)
Frequently used configuration
# Plot title.
set title "the plot"
# Labels.
set xlabel "abc"
set ylabel "def"
# Grid.
set grind
# Output format, 'help set term' for all output formats.
set term svg
# Output file.
set output "out.svg"
# Make axis logarithmic to given base.
set logscale x 2
# Change separator, default is whitespace.
set datafile separator ","
Plot
# With specific style (eg lines, linespoint, boxes, steps, impulses, ..).
plot "<data_file>" with <plot_style>
> cat data.txt
1 1 3
2 2 2
3 3 1
4 2 2
# Plot specific column.
plot "data.txt" using 1:2, "data.txt" using 1:3
# Equivalent using the special file "", which re-uses the previous input file.
plot "data.txt" using 1:2, "" using 1:3
# Plot piped data.
plot "< head -n2 data.txt"
# Plot with alternate title.
plot "data.txt" title "moose"
Example: Specify range directly during plot
# Plot two functions in the range 0-10.
plot [0:10] 10*x, 20*x
Example: multiple data sets in plot
# file: mem_lat.plot
set title "memory latency (different strides)"
set xlabel "array in KB"
set ylabel "cycles / access"
set logscale x 2
plot "stride_32.txt" title "32" with linespoints, \
"stride_64.txt" title "64" with linespoints, \
"stride_128.txt" title "128" with linespoints, \
"stride_256.txt" title "256" with linespoints, \
"stride_512.txt" title "512" with linespoints
On Linux x86_64, mem_lat.c provides an example which can
be run as follows.
gcc -o mem_lat mem_lat.c -g -O3 -Wall -Werror
for stride in 32 64 128 256 512; do \
taskset -c 1 ./mem_lat 128 $stride | tee stride_$stride.txt ; \
done
gnuplot -p -c mem_lat.plot
restic(1)
Create new snapshot repository
# Create a local backup repository.
restic -r <path> init
# Create a backup repository on a remote host.
restic -r sftp:user@host:<path> init
Example: Restore file pattern from latest snapshot
Restore files matching <file_pattern> from the latest snapshot (pseudo
snapshot ID) into <dest>.
restic -r <repo> restore -i <file_pattern> --target <dest> latest
Mount snapshots
Mount snapshots as user filesystem (fuse) to given mount point.
restic -r <repo> mount <mntpoint>
# Mounted snapshots can be limited by host.
restic -r <repo> mount --host <host> <mntpoint>
# Mounted snapshots can be limited by path (abs path).
restic -r <repo> mount --path <abspath> <mntpoint>
Repository maintenance
Check the repository for errors and report them.
restic -r <repo> check
Check the repository for non-referenced data and remove it.
restic -r <repo> prune
References
qrencode(1)
qrencode
-s N pixels per feature length
Generate wifi qr code for WPA2 secured network.
# Generate on terminal.
qrencode -t ansiutf8 'WIFI:S:<wifiname>;T:WPA2;P:<wifipasswd>;;'
# Generate picture for printing.
qrencode -t png -o wifi.png 'WIFI:S:<wifiname>;T:WPA2;P:<wifipasswd>;;'
Process management & inspection
lsof(8)
lsof
-r <s> ..... repeatedly execute command ervery <s> seconds
-a ......... AND slection filters instead ORing (OR: default)
-p <pid> ... filter by <pid>
+fg ........ show file flags for file descripros
-n ......... don't convert network addr to hostnames
-P ......... don't convert network port to service names
-i <@h[:p]>. show connections to h (hostname|ip addr) with optional port p
-s <p:s> ... in conjunction with '-i' filter for protocol <p> in state <s>
-U ......... show unix domain sockets ('@' indicates abstract sock name, see unix(7))
file flags:
R/W/RW ..... read/write/read-write
CR ......... create
AP ......... append
TR ......... truncate
-s protocols
TCP, UDP
-s states (TCP)
CLOSED, IDLE, BOUND, LISTEN, ESTABLISHED, SYN_SENT, SYN_RCDV, ESTABLISHED,
CLOSE_WAIT, FIN_WAIT1, CLOSING, LAST_ACK, FIN_WAIT_2, TIME_WAIT
-s states (UDP)
Unbound, Idle
Examples
File flags
Show open files with file flags for process:
lsof +fg -p <pid>
Open TCP connections
Show open tcp connections for $USER:
lsof -a -u $USER -i TCP
Note: -a ands the results. If -a is not given all open files matching
$USER and all tcp connections are listed (ored).
Open connection to specific host
Show open connections to localhost for $USER:
lsof -a -u $USER -i @localhost
Open connection to specific port
Show open connections to port :1234 for $USER:
lsof -a -u $USER -i :1234
IPv4 TCP connections in ESTABLISHED state
lsof -i 4TCP -s TCP:ESTABLISHED
List open files in a mounted directory.
This may help to find which processes keep devices busy when trying to unmount and the device is currently busy.
# Assuming /proc is a mount point.
lsof /proc
pidstat(1)
pidstat [opt] [interval] [cont]
-U [user] show username instead UID, optionally only show for user
-r memory statistics
-d I/O statistics
-h single line per process and no lines with average
Page fault and memory utilization
pidstat -r -p <pid> [interval] [count]
minor_pagefault: Happens when the page needed is already in memory but not
allocated to the faulting process, in that case the kernel
only has to create a new page-table entry pointing to the
shared physical page (not required to load a memory page from
disk).
major_pagefault: Happens when the page needed is NOT in memory, the kernel
has to create a new page-table entry and populate the
physical page (required to load a memory page from disk).
I/O statistics
pidstat -d -p <pid> [interval] [count]
pgrep(1)
pgrep [opts] <pattern>
-n only list newest matching process
-u <usr> only show matching for user <usr>
-l additionally list command
-a additionally list command + arguments
-x match exactly
Debug newest process
For example attach gdb to newest zsh process from $USER.
gdb -p $(pgrep -n -u $USER zsh)
ps(1)
ps [opt]
opt:
--no-header .... do not print column header
-o <OUT> ....... comma separated list of output columns
-p <PID> ....... only show pid
-C <name> ...... only show processes matching name
-T ............. list threads
--signames ..... use short signames instead bitmasks
Set
PS_FORMATenv variable to setup default output columns.
Frequently used output columns
pid process id
ppid parent process id
pgid process group id
tid thread id
comm name of process
cmd name of process + args (full)
etime elapsed time (since process started)
user user owning process
thcount thread count of process
nice nice value (-20 highest priority to 19 lowest)
pcpu cpu utilization (percent)
pmem physical resident set (rss) (percent)
rss physical memory (in kb)
vsz virtual memory (in kb)
sig mask of pending signals
sigcatch mask of caught signals
sigignore mask of ignored signals
sigmask mask of blocked signals
Example: Use output for scripting
# Print the cpu affinity for each thread of process 31084.
for tid in $(ps -o tid --no-header -T -p 31084); do
taskset -c -p $tid;
done
Example: Watch processes by name
watch -n1 ps -o pid,pcpu,pmem,rss,vsz,state,user,comm -C fish
Example: Show signal information
# With signal masks.
ps -o pid,user,sig,sigcatch,sigignore,sigmask,comm -p 66570
# With signal names.
ps --signames -o pid,user,sig,sigcatch,sigignore,sigmask,comm -p 66570
pmap(1)
pmap [opts] <pid>
Dump virtual memory map of process.
Compared to /proc/<pid>/maps it shows the size of the mappings.
opts:
-p show full path in the mapping
-x show details (eg RSS usage of each segment)
pstack(1)
pstack <pid>
Dump stack for all threads of process.
taskset(1)
Set cpu affinity for new processes or already running ones.
# Pin all (-a) tasks of new command on cores 0,1,2,4.
taskset -ac 0-2,4 CMD [ARGS]
# Pin all tasks of running PID onto cores 0,2,4.
taskset -ac 0-5:2 -p PID
Example
Utility script to extract cpu lists grouped by the last-level-cache.
import subprocess
res = subprocess.run(["lscpu", "-p=cpu,cache"], capture_output=True, check=True)
LLC2CPU = dict()
for line in res.stdout.decode().splitlines():
if line.startswith("#"):
continue
cpu, cache = line.split(",")
llc = cache.split(":")[-1]
LLC2CPU.setdefault(llc, list()).append(int(cpu))
LLC2RANGE = dict()
for llc, cpus in LLC2CPU.items():
first_cpu = cpus[0]
prev_cpu = cpus[0]
for cpu in cpus[1:]:
if cpu != prev_cpu + 1:
LLC2RANGE.setdefault(llc, list()).append(f"{first_cpu}-{prev_cpu}")
# New range begins.
first_cpu = cpu
prev_cpu = cpu
# Trailing range.
LLC2RANGE.setdefault(llc, list()).append(f"{first_cpu}-{prev_cpu}")
print(LLC2RANGE)
nice(1)
Adjust niceness of a new command or running process.
Niceness influences the scheduling priority and ranges between:
-20most favorable19least favorable
# Adjust niceness +5 for the launched process.
nice -n 5 yes
# Adjust niceness of running process.
renice -n 5 -p PID
Trace and Profile
/usr/bin/time(1)
# statistics of process run
/usr/bin/time -v <cmd>
strace(1)
strace [opts] [prg]
-f .......... follow child processes on fork(2)
-ff ......... follow fork and separate output file per child
-p <pid> .... attach to running process
-s <size> ... max string size, truncate of longer (default: 32)
-e <expr> ... expression for trace filtering
-o <file> ... log output into <file>
-c .......... dump syscall statitics at the end
-C .......... like -c but dump regular ouput as well
-k .......... dump stack trace for each syscall
-P <path> ... only trace syscall accesing path
-y .......... print paths for FDs
-tt ......... print absolute timestamp (with us precision)
-r .......... print relative timestamp
-z .......... log only successful syscalls
-Z .......... log only failed syscalls
-n .......... print syscall numbers
-y .......... translate fds (eg file path, socket)
-yy ......... translate fds with all information (eg IP)
-x .......... print non-ASCII chars as hex string
-v .......... print all arguments (non-abbreviated)
<expr>:
trace=syscall[,syscall] .... trace only syscall listed
trace=file ................. trace all syscall that take a filename as arg
trace=process .............. trace process management related syscalls
trace=signal ............... trace signal related syscalls
signal ..................... trace signals delivered to the process
Examples
Trace open(2) & socket(2) syscalls for a running process + child processes:
strace -f -e trace=open,socket -p <pid>
Trace signals delivered to a running process:
strace -e signal -e 'trace=!all' -p <pid>
Show successful calls to perf_event_open((2) without abbreviating arguments.
strace -v -z -e trace=perf_event_open perf stat -e cycles ls
ltrace(1)
ltrace [opts] [prg]
-f .......... follow child processes on fork(2)
-p <pid> .... attach to running process
-o <file> ... log output into <file>
-l <filter> . show who calls into lib matched by <filter>
-C .......... demangle
-e <filter> . show calls symbols matched by <filter>
-x <filter> . which symbol table entry points to trace
(can be of form sym_pattern@lib_pattern)
-n <num> number of spaces to indent nested calls
Example
List which program/libs call into libstdc++:
ltrace -l '*libstdc++*' -C -o ltrace.log ./main
List calls to specific symbols:
ltrace -e malloc -e free ./main
Trace symbols from dlopen(3)ed libraries.
# Assume libfoo.so would be dynamically loaded via dlopen.
ltrace -x '@libfoo.so'
# Trace all dlopened symbols.
ltrace -x '*'
# Trace all symbols from dlopened libraries which name match the
# pattern "liby*".
ltrace -x '@liby*'
# Trace symbol "foo" from all dlopened libraries matching the pattern.
ltrace -x 'foo@liby*'
perf(1)
perf list show supported hw/sw events & metrics
-v ........ print longer event descriptions
--details . print information on the perf event names
and expressions used internally by events
perf stat
-p <pid> ..... show stats for running process
-o <file> .... write output to file (default stderr)
-I <ms> ...... show stats periodically over interval <ms>
-e <ev> ...... select event(s)
-M <met> ..... print metric(s), this adds the metric events
--all-user ... configure all selected events for user space
--all-kernel . configure all selected events for kernel space
perf top
-p <pid> .. show stats for running process
-F <hz> ... sampling frequency
-K ........ hide kernel threads
perf record
-p <pid> ............... record stats for running process
-o <file> .............. write output to file (default perf.data)
-F <hz> ................ sampling frequency
--call-graph <method> .. [fp, dwarf, lbr] method how to caputre backtrace
fp : use frame-pointer, need to compile with
-fno-omit-frame-pointer
dwarf: use .cfi debug information
lbr : use hardware last branch record facility
-g ..................... short-hand for --call-graph fp
-e <ev> ................ select event(s)
--all-user ............. configure all selected events for user space
--all-kernel ........... configure all selected events for kernel space
-M intel ............... use intel disassembly in annotate
perf report
-n .................... annotate symbols with nr of samples
--stdio ............... report to stdio, if not presen tui mode
-g graph,0.5,callee ... show callee based call chains with value >0.5
Useful <ev>:
page-faults
minor-faults
major-faults
cpu-cycles`
task-clock
Select specific events
Events to sample are specified with the -e option, either pass a comma
separated list or pass -e multiple times.
Events are specified in the following form name[:modifier]. The list and
description of the modifier can be found in the
perf-list(1) manpage under EVENT MODIFIERS.
# L1 i$ misses in user space
# L2 i$ stats in user/kernel space mixed
# Sample specified events.
perf stat -e L1-icache-load-misses:u \
-e l2_rqsts.all_code_rd:uk,l2_rqsts.code_rd_hit:k,l2_rqsts.code_rd_miss:k \
-- stress -c 2
The --all-user and --all-kernel options append a :u and :k modifier to
all specified events. Therefore the following two command lines are equivalent.
# 1)
perf stat -e cycles:u,instructions:u -- ls
# 2)
perf stat --all-user -e cycles,instructions -- ls
Raw events
In case perf does not provide a symbolic name for an event, the event can be
specified in a raw form as r + UMask + EventCode.
The following is an example for the L2_RQSTS.CODE_RD_HIT event
with EventCode=0x24 and UMask=0x10 on my laptop with a sandybridge uarch.
perf stat -e l2_rqsts.code_rd_hit -e r1024 -- ls
# Performance counter stats for 'ls':
#
# 33.942 l2_rqsts.code_rd_hit
# 33.942 r1024
Find raw performance counter events (intel)
The intel/perfmon repository provides a performance event
databases for the different intel uarchs.
The table in mapfile.csv can be used to lookup the
corresponding uarch, just grab the family model from the procfs.
cat /proc/cpuinfo | awk '/^vendor_id/ { V=$3 }
/^cpu family/ { F=$4 }
/^model\s*:/ { printf "%s-%d-%x\n",V,F,$3 }'
The table in performance monitoring events describes how events are sorted into the different files.
Raw events for perfs own symbolic names
Perf also defines some own symbolic names for events. An example is the
cache-references event. The perf_event_open(2) manpage
gives the following description.
perf_event_open(2)
PERF_COUNT_HW_CACHE_REFERENCES
Cache accesses. Usually this indicates Last Level Cache accesses but this
may vary depending on your CPU. This may include prefetches and coherency
messages; again this depends on the design of your CPU.
The sysfs can be consulted to get the concrete performance counter on the
given system.
cat /sys/devices/cpu/events/cache-misses
# event=0x2e,umask=0x41
Flamegraph
Flamegraph with single event trace
perf record -g -e cpu-cycles -p <pid>
perf script | FlameGraph/stackcollapse-perf.pl | FlameGraph/flamegraph.pl > cycles-flamegraph.svg
Flamegraph with multiple event traces
perf record -g -e cpu-cycles,page-faults -p <pid>
perf script --per-event-dump
# fold & generate as above
Examples
Estimate max instructions per cycle
#define NOP4 "nop\nnop\nnop\nnop\n"
#define NOP32 NOP4 NOP4 NOP4 NOP4 NOP4 NOP4 NOP4 NOP4
#define NOP256 NOP32 NOP32 NOP32 NOP32 NOP32 NOP32 NOP32 NOP32
#define NOP2048 NOP256 NOP256 NOP256 NOP256 NOP256 NOP256 NOP256 NOP256
int main() {
for (unsigned i = 0; i < 2000000; ++i) {
asm volatile(NOP2048);
}
}
perf stat -e cycles,instructions ./noploop
# Performance counter stats for './noploop':
#
# 1.031.075.940 cycles
# 4.103.534.341 instructions # 3,98 insn per cycle
Caller vs callee callstacks
The following gives an example for a scenario where we have the following calls
main -> do_foo() -> do_work()main -> do_bar() -> do_work()
perf report --stdio -g graph,caller
# Children Self Command Shared Object Symbols
# ........ ........ ....... .................... .................
#
# 49.71% 49.66% bench bench [.] do_work
# |
# --49.66%--_start <- callstack bottom
# __libc_start_main
# 0x7ff366c62ccf
# main
# |
# |--25.13%--do_bar
# | do_work <- callstack top
# |
# --24.53%--do_foo
# do_work
perf report --stdio -g graph,callee
# Children Self Command Shared Object Symbols
# ........ ........ ....... .................... .................
#
# 49.71% 49.66% bench bench [.] do_work
# |
# ---do_work <- callstack top
# |
# |--25.15%--do_bar
# | main
# | 0x7ff366c62ccf
# | __libc_start_main
# | _start <- callstack bottom
# |
# --24.55%--do_foo
# main
# 0x7ff366c62ccf
# __libc_start_main
# _start <- callstack bottom
References
- intel/perfmon - intel PMU event database per uarch
- intel/perfmon-html - a html rendered version of the PMU events with search
- intel/perfmon/mapfile.csv - processor family to uarch mapping
- linux/perf/events - x86 PMU events known to perf tools
- linux/arch/events - x86 PMU events linux kernel
- wikichip - computer architecture wiki
- perf-list(1) - manpage
- perf_event_open(2) - manpage
- intel/sdm - intel software developer manuals (eg Optimization Reference Manual)
OProfile
operf -g -p <pid>
-g ...... caputre call-graph information
opreport [opt] FILE
show time spent per binary image
-l ...... show time spent per symbol
-c ...... show callgraph information (see below)
-a ...... add column with time spent accumulated over child nodes
ophelp show supported hw/sw events
callgrind
Callgrind is a tracing profiler which records the function call history of a target program and collects the number of executed instructions. It is part of the valgrind tool suite.
Profiling data is collected by instrumentation rather than sampling of the target program.
Callgrind does not capture the actual time spent in a function but computes the
inclusive & exclusive cost of a function based on the instructions fetched
(Ir = Instruction read). This provides reproducibility and high-precision and
is a major difference to sampling profilers like perf or vtune.
Therefore effects like slow IO are not reflected, which should be kept in mind
when analyzing callgrind results.
By default the profiler data is dumped when the target process is terminating, but callgrind_control allows for interactive control of callgrind.
# Run a program under callgrind.
valgrind --tool=callgrind -- <prog> [<args>]
# Interactive control of callgrind.
callgrind_control [opts]
opts:
-b ............. show current backtrace
-e ............. show current event counters
-s ............. show current stats
--dump[=file] .. dump current collection
-i=on|off ...... turn instrumentation on|off
Results can be analyzed by using one of the following tools
- callgrind_annotate (cli)
# Show only specific trace events (default is all). callgrind_annotate --show=Ir,Dr,Dw [callgrind_out_file] - kcachegrind (ui)
The following is a collection of frequently used callgrind options.
valgrind --tool=callgrind [opts] -- <prog>
opts:
--callgrind-out-file=<file> .... output file, rather than callgrind.out.<pid>
--dump-instr=<yes|no> .......... annotation on instrucion level,
allows for asm annotations
--instr-atstart=<yes|no> ....... control if instrumentation is enabled from
beginning of the program
--separate-threads=<yes|no> .... create separate output files per thread,
appends -<thread_id> to the output file
--cache-sim=<yes|no> ........... control if cache simulation is enabled
Trace events
By default callgrind collects following events:
Ir: Instruction read
Callgrind also provides a functional cache simulation with their own model,
which is enabled by passing --cache-sim=yes.
This simulates a 2-level cache hierarchy with separate L1 instruction and
data caches (L1i/ L1d) and a unified last level (LL) cache.
When enabled, this collects the following additional events:
I1mr: L1 cache miss on instruction readILmr: LL cache miss on instruction readDr: Data reads accessD1mr: L1 cache miss on data readDLmr: LL cache miss on data readDw: Data write accessD1mw: L1 cache miss on data writeDLmw: LL cache miss on data write
Profile specific part of the target
Programmatically enable/disable instrumentation using the macros defined in the callgrind header.
#include <valgrind/callgrind.h>
int main() {
// init ..
CALLGRIND_START_INSTRUMENTATION;
compute();
CALLGRIND_STOP_INSTRUMENTATION;
// shutdown ..
}
In this case, callgrind should be launched with
--instr-atstart=no.
Alternatively instrumentation can be controlled with callgrind_control -i on/off.
The files cg_example.cc and Makefile provide a full example.
valgrind(1)
Memcheck --tool=memcheck
Is the default tool when invoking valgrind without explicitly specifying
--tool.
Memory checker used to identify:
- memory leaks
- out of bound accesses
- uninitialized reads
valgrind [OPTIONS] PROGRAM [ARGS]
--log-file=FILE Write valgrind output to FILE.
--leak-check=full Enable full leak check.
--track-origins=yes Show origins of undefined values.
--keep-debuginfo=no|yes Keep symbols etc for unloaded code.
--gen-suppressions=yes Generate suppressions file from the run.
--suppressions=FILE Load suppressions file.
vtune(1)
Vtune offers different analysis. Run vtune -collect help to list the
availale analysis.
Profiling
The following shows some common flows with the hotspot analsysis
as an example.
# Launch and profile process.
vtune -collect hotspots [opts] -- target [args]
# Attach and profile running process.
vtune -collect hotspots [opts] -target-pid <pid>
Some common options are the following.
-r <dir> output directory for the profile
-no-follow-child dont attach to to child processes (default is to follow)
-start-paused start with paused profiling
Analyze
vtune-gui <dir>
Programmatically control sampling
Vtune offers an API to resume and pause the profile collection from within the profilee itself. This can be helpful if either only a certain phase should be profiled or some phase should be skipped.
The following gives an example where only one phase in the program is profiled.
The program makes calls to the vtune API to resume and pause the collection,
while vtune is invoked with -start-paused to pause profiling initially.
#include <ittnotify.h>
void init();
void compute();
void shutdown();
int main() {
init();
__itt_resume();
compute();
__itt_pause();
shutdown();
return 0;
}
The makefile gives an example how to build and profile the application.
VTUNE ?= /opt/intel/oneapi/vtune/latest
main: main.c
gcc -o $@ $^ -I$(VTUNE)/include -L$(VTUNE)/lib64 -littnotify
vtune: main
$(VTUNE)/bin64/vtune -collect hotspots -start-paused -- ./main
tracy(1)
Tracy is a frame profiler, supporting manual code instrumentation and providing a sampling profiler.
One can either record and visualize the profiling data live using
tracy-profiler or record the profiling data to a file using tracy-capture.
tracy-profiler [file] [-p port]
tracy-capture -o file [-f] [-p port]
-f overwrite <file> if it exists
Example
The example showcases different cases:
- Use tracy from a single binary. In that case the
TracyClient.cppcan be directly linked / included in the instrumented binary. - Use tracy from different binaries (eg main executable + shared library). In
this case the
TracyClient.cppshould be compiled into its own shared library, such that there is a single tracy client. - Use tracy from different binaries on windows. In this case the
TracyClient.cppmust be compiled again into a separate shared library, while definingTRACY_EXPORTS. The code being instrumented must be compiled withTRACY_IMPORTSdefined.
An instrumented c++ example:
#include <chrono>
#include <thread>
#include <tracy/Tracy.hpp>
#ifdef USE_FOO
extern "C" void foo_comp_hook(int64_t);
#endif
void init() {
// Create a named zone (active for the current scope).
// Name will be used when rendering the zone in the thread timeline.
ZoneScopedN("init()");
// Set explicit color for the rendered zone.
ZoneColor(0xff0000);
std::this_thread::sleep_for(std::chrono::seconds(1));
}
void comp(const char* name) {
// Track call count.
static int64_t ccnt = 0;
ccnt += 1;
// Create an unnamed zone for the current scope.
ZoneScoped;
// Name the zone by formatting the name dynamically.
// This name is shown for the zone in the thread timeline, however
// in the zone statistics they are all accounted under one common
// zone "comp".
ZoneNameF("comp(%s)", name);
// Additional text to attach to the zone.
ZoneTextF("text(%s)", name);
// Additional value to attach to the zone measurement.
ZoneValue(ccnt);
// Statistics for dynamic names, text and values can be looked at in the zone
// statistics.There measurements can be grouped by different categories.
// Add a simple plot.
TracyPlot("comp-plot", ccnt % 4);
std::this_thread::sleep_for(std::chrono::milliseconds(100));
#ifdef USE_FOO
foo_comp_hook(ccnt);
#endif
}
void post_comp() {
// Create an unnamed zone for the current scope and capture callstack (max
// depth 10). Capturing callstack requires platform with TRACY_HAS_CALLSTACK
// support.
ZoneScopedS(10);
// Name the zone, w/o formatting.
const char name[] = "post_comp()";
ZoneName(name, sizeof(name));
// Add trace messages to the timeline.
TracyMessageL("start sleep in post_comp()");
std::this_thread::sleep_for(std::chrono::milliseconds(50));
TracyMessageL("end sleep in post_comp()");
}
void fini() {
// Create a named zone with an explicit color.
ZoneScopedNC("fini()", 0x00ff00);
std::this_thread::sleep_for(std::chrono::seconds(1));
}
int main() {
// Create a named zone.
ZoneScopedN("main()");
init();
int step = 0;
while (step++ < 10) {
// Create a frame message, this start a new frame with the name
// "step" and end the previous frame with the name "step".
FrameMarkNamed("step");
// Create a named scope.
ZoneScopedN("step()");
comp("a");
comp("b");
comp("c");
post_comp();
}
fini();
}
An instrumented c example:
#include <stdint.h>
#include <inttypes.h>
#include <stdio.h>
#include <tracy/TracyC.h>
static void comp_helper(int64_t i) {
char buf[64];
int cnt = snprintf(buf, sizeof(buf), "helper(%" PRId64 ")", i);
// Create an active unnamed zone.
TracyCZone(ctx, 1);
// Name the zone.
TracyCZoneName(ctx, buf, cnt);
// Add custom text to the zone measurement.
TracyCZoneText(ctx, buf, cnt);
// Add custom value to the zone measurement.
TracyCZoneValue(ctx, i);
for (int ii = 0; ii < i * 100000; ++ii) {
/* fake work */
}
// End the zone measurement.
TracyCZoneEnd(ctx);
}
void foo_comp_hook(int64_t cnt) {
// Create an active named zone.
TracyCZoneN(ctx, "foo", 1);
for (int i = 0; i < cnt; ++i) {
// Plot value.
TracyCPlot("foo_comp_hook", cnt + i);
comp_helper(i);
}
// Configure plot "foo", probably best done once during initialization..
TracyCPlotConfig("foo", TracyPlotFormatNumber, 1 /* step */, 1 /* fill */,
0xff0000);
// Plot value.
TracyCPlot("foo", cnt);
// End the zone measurement.
TracyCZoneEnd(ctx);
}
Raw build commands to demonstrate compiling tracy w/o cmake, in case we need
to integrate it into a different build system.
B := BUILD
main: $(B)/main-static $(B)/main-dynamic $(B)/main-dynamic-win
tracy: $(B)/tracy
.PHONY: main tracy
# -- TRACY STATIC ---------------------------------------------------------------
$(B)/main-static: main.cpp | $(B)
clang++ -DTRACY_ENABLE -I$(B)/tracy/public -o $@ $^ $(B)/tracy/public/TracyClient.cpp
# -- TRACY DYNAMIC --------------------------------------------------------------
$(B)/main-dynamic: main.cpp $(B)/foo.so $(B)/TracyClient.so | $(B)
clang++ -DTRACY_ENABLE -I$(B)/tracy/public -DUSE_FOO -o $@ $^
$(B)/foo.so: foo.c $(B)/TracyClient.so
clang -DTRACY_ENABLE -I$(B)/tracy/public -fPIC -shared -o $@ $^
$(B)/TracyClient.so: $(B)/tracy/public/TracyClient.cpp
clang++ -DTRACY_ENABLE -I$(B)/tracy/public -fPIC -shared -o $@ $^
# -- TRACY DYNAMIC WINDOWS ------------------------------------------------------
$(B)/main-dynamic-win: main.cpp $(B)/foo.dll $(B)/TracyClient.dll
@# eg run with wine
zig c++ -target x86_64-windows -DTRACY_ENABLE -DTRACY_IMPORTS -DUSE_FOO -o $@ $^ -I $(B)/tracy/public
$(B)/foo.dll: foo.c $(B)/TracyClient.dll
zig c++ -target x86_64-windows -DTRACY_ENABLE -DTRACY_IMPORTS -fPIC -shared -o $@ $^ -I $(B)/tracy/public
$(B)/TracyClient.dll: $(B)/tracy/public/TracyClient.cpp
@# win libs from 'pragma comment(lib, ..)'
zig c++ -target x86_64-windows -DTRACY_ENABLE -DTRACY_EXPORTS -fPIC -shared -o $@ $^ -lws2_32 -ldbghelp -ladvapi32 -luser32
# -- TRACY ----------------------------------------------------------------------
# Get latest tracy and build profiler.
$(B)/tracy: $(B)
cd $(B); bash $(CURDIR)/get-tracy.sh
.PHONY: $(B)/tracy
$B:
mkdir -p $(B)
.PHONY: $(B)
# -- CLEAN ----------------------------------------------------------------------
clean:
$(RM) $(B)/*.so $(B)/*.dll $(B)/*.pdb $(B)/*.lib $(B)/main*
distclean:
rm -rf $(B)
Find
get-tracy.shhere.
Debug
gdb(1)
CLI
gdb [opts] [prg [-c coredump | -p pid]]
gdb [opts] --args prg <prg-args>
opts:
-p <pid> attach to pid
-c <coredump> use <coredump>
-x <file> execute script <file> before prompt
-ex <cmd> execute command <cmd> before prompt
--tty <tty> set I/O tty for debugee
--batch run in batch mode, exit after processing options (eg used
for scripting)
--batch-silent link --batch, but surpress gdb stdout
Interactive usage
Misc
apropos <regex>
Search commands matching regex.
tty <tty>
Set <tty> as tty for debugee.
Make sure nobody reads from target tty, easiest is to spawn a shell
and run following in target tty:
> while true; do sleep 1024; done
sharedlibrary [<regex>]
Load symbols of shared libs loaded by debugee. Optionally use <regex>
to filter libs for symbol loading.
display [/FMT] <expr>
Print <expr> every time debugee stops. Eg print next instr, see
examples below.
undisplay [<num>]
Delete display expressions either all or one referenced by <num>.
info display
List display expressions.
info sharedlibrary [<regex>]
List shared libraries loaded. Optionally use <regex> to filter.
Breakpoints
break [-qualified] <sym> thread <tnum>
Set a breakpoint only for a specific thread.
-qualified: Treat <sym> as fully qualified symbol (quiet handy to set
breakpoints on C symbols in C++ contexts)
break <sym> if <cond>
Set conditional breakpoint (see examples below).
delete [<num>]
Delete breakpoint either all or one referenced by <num>.
info break
List breakpoints.
cond <bp> <cond>
Make existing breakpoint <bp> conditional with <cond>.
cond <bp>
Remove condition from breakpoint <bp>.
tbreak
Set temporary breakpoint, will be deleted when hit.
Same syntax as `break`.
rbreak <regex>
Set breakpoints matching <regex>, where matching internally is done
on: .*<regex>.*
command [<bp_list>]
Define commands to run after breakpoint hit. If <bp_list> is not
specified attach command to last created breakpoint. Command block
terminated with 'end' token.
<bp_list>: Space separates list, eg 'command 2 5-8' to run command
for breakpoints: 2,5,6,7,8.
save break <file>
Save breakpoints to <file>. Can be loaded with the `source` command.
Watchpoints
watch [-location|-l] <expr> [thread <tnum>]
Create a watchpoint for <expr>, will break if <expr> is written to.
Watchpoints respect scope of variables, -l can be used to watch the
memory location instead.
rwatch ...
Sets a read watchpoint, will break if <expr> is read from.
awatch ...
Sets an access watchpoint, will break if <expr> is written to or read
from.
Catchpoints
catch load [<regex>]
Stop when shared libraries are loaded, optionally specify a <regex>
to stop only on matches.
catch unload [<regex>]
Stop when shared libraries are unloaded, optionally specify a <regex>
to stop only on matches.
catch throw
Stop when an exception is thrown.
catch rethrow
Stop when an exception is rethrown.
catch catch
Stop when an exception is caught.
catch fork
Stop at calls to fork (also stops at clones, as some systems
implement fork via clone).
catch syscall [<syscall> <syscall> ..]
Stop at syscall. If no argument is given, stop at all syscalls.
Optionally give a list of syscalls to stop at.
Inspection
info functions [<regex>]
List functions matching <regex>. List all functions if no <regex>
provided.
info variables [<regex>]
List variables matching <regex>. List all variables if no <regex>
provided.
info register [<reg> <reg> ..]
Dump content of all registers or only the specified <reg>ister.
Signal handling
info handle [<signal>]
Print how to handle <signal>. If no <signal> specified print for all
signals.
handle <signal> <action>
Configure how gdb handles <signal> sent to debugee.
<action>:
stop/nostop Catch signal in gdb and break.
print/noprint Print message when gdb catches signal.
pass/nopass Pass signal down to debugee.
catch signal <signal>
Create a catchpoint for <signal>.
Multi-threading
info thread
List all threads.
thread apply <id> [<id>] <command>
Run command on all threads listed by <id> (space separated list).
When 'all' is specified as <id> the <command> is run on all threads.
thread name <name>
The <name> for the current thread.
Multi-process
set follow-fork-mode <child | parent>
Specify which process to follow when debuggee makes a fork(2)
syscall.
set detach-on-fork <on | off>
Turn on/off detaching from new child processes (on by default).
Turning this off allows to debug multiple processes (inferiors) with
one gdb session.
info inferiors
List all processes gdb debugs.
inferior <id>
Switch to inferior with <id>.
Scheduling
set schedule-multiple <on | off>
on: Resume all threads of all processes (inferiors) when continuing
or stepping.
off: (default) Resume only threads of current process (inferior).
Shell commands
shell <shell_cmd>
Run the shell_cmd and print the output, can also contain a pipeline.
pipe <gdb_cmd> | <shell_cmd>
Evaluate the gdb_cmd and run the shell_cmd which receives the output
of the gdb_cmd via stdin.
Source file locations
dir <path>
Add <path> to the beginning of the searh path for source files.
show dir
Show current search path.
set substitute-path <from> <to>
Add substitution rule checked during source file lookup.
show substitute-path
Show current substitution rules.
Configuration
set disassembly-flavor <intel | att>
Set the disassembly style "flavor".
set pagination <on | off>
Turn on/off gdb's pagination.
set breakpoint pending <on | off | auto>
on: always set pending breakpoints.
off: error when trying to set pending breakpoints.
auto: interatively query user to set breakpoint.
set print pretty <on | off>
Turn on/off pertty printing of structures.
set style enabled <on | off>
Turn on/off styling (eg colored output).
set logging <on | off>
Enable output logging to file (default gdb.txt).
set logging file <fname>
Change output log file to <fname>
set logging redirect <on | off>
on: only log to file.
off: log to file and tty.
set logging overwrite <on | off>
on: Truncate log file on each run.
off: Append to logfile (default).
set trace-commands <on | off>
on: Echo comamands executed (good with logging).
off: Do not echo commands executedt (default).
set history filename <fname>
Change file where to save and restore command history to and from.
set history <on | off>
Enable or disable saving of command history.
set exec-wrapper <cli>
Set an exec wrapper which sets up the env and execs the debugee.
Logging options should be configured before logging is turned on.
Text user interface (TUI)
C-x a Toggle UI.
C-l Redraw UI (curses UI can be messed up after the debugee prints to
stdout/stderr).
C-x o Change focus.
User commands (macros)
Gdb allows to create & document user commands as follows:
define <cmd>
# cmds
end
document <cmd>
# docu
end
To get all user commands or documentations one can use:
help user-defined
help <cmd>
Hooks
Gdb allows to create two types of command hooks
hook-will be run before<cmd>hookpost-will be run after<cmd>
define hook-<cmd>
# cmds
end
define hookpost-<cmd>
# cmds
end
Examples
Automatically print next instr
When ever the debugee stops automatically print the memory at the current
instruction pointer ($rip x86) and format as instruction /i.
# rip - x86
display /i $rip
# step instruction, after the step the next instruction is automatically printed
si
Conditional breakpoints
Create conditional breakpoints for a function void foo(int i) in the debugee.
# Create conditional breakpoint
b foo if i == 42
b foo # would create bp 2
# Make existing breakpoint conditional
cond 2 i == 7
Set breakpoint on all threads except one
Create conditional breakpoint using the $_thread convenience
variable.
# Create conditional breakpoint on all threads except thread 12.
b foo if $_thread != 12
Catch SIGSEGV and execute commands
This creates a catchpoint for the SIGSEGV signal and attached the command
to it.
catch signal SIGSEGV
command
bt
c
end
Run backtrace on thread 1 (batch mode)
gdb --batch -ex 'thread 1' -ex 'bt' -p <pid>
Script gdb for automating debugging sessions
To script gdb add commands into a file and pass it to gdb via -x.
For example create run.gdb:
set pagination off
break mmap
command
info reg rdi rsi rdx
bt
c
end
#initial drop
c
This script can be used as:
gdb --batch -x ./run.gdb -p <pid>
Hook to automatically save breakpoints on quit
define break-save
save breakpoint $arg0.gdb.bp
end
define break-load
source $arg0.gdb.bp
end
define hook-quit
break-save quit
end
Watchpoint on struct / class member
A symbolic watchpoint defined on a member variable for debugging is only valid as long as the expression is in scope. Once out of scope the watchpoint gets deleted.
When debugging some memory corruption we want to keep the watchpoint even the expression goes out of scope to find the location that overrides the variable and introduces the corruption.
(gdb) l
1 struct S { int v; };
2
3 void set(struct S* s, int v) {
4 s->v = v;
5 }
6
7 int main() {
8 struct S s;
9 set(&s, 1);
10 set(&s, 2);
11 set(&s, 3);
...
(gdb) s
set (s=0x7fffffffe594, v=1) at test.c:4
4 s->v = v;
# Define a new watchpoint on the member of the struct. The expression however
# is only valid in the current functions scope.
(gdb) watch s->v
Hardware watchpoint 2: s->v
(gdb) c
Hardware watchpoint 2: s->v
Old value = 0
New value = 1
set (s=0x7fffffffe594, v=1) at test.c:5
5 }
# The watchpoint gets deleted as soon as we leave the function scope.
(gdb) c
Watchpoint 2 deleted because the program has left the block in
which its expression is valid.
main () at test.c:10
10 set(&s, 2);
# Define the watchpoint on the location of the object to watch.
(gdb) watch -l s->v
# This is equivalent to the following.
(gdb) p &s->v
$1 = (int *) 0x7fffffffe594
# Define a watchpoint to the address of the member variable of the s instance.
# This of course only makes sense as long as the s instance is not moved in memory.
(gdb) watch *0x7fffffffe594
Hardware watchpoint 3: *0x7fffffffe594
(gdb) c
Hardware watchpoint 3: *0x7fffffffe594
Old value = 1
New value = 2
set (s=0x7fffffffe594, v=2) at test.c:5
5 }
(gdb) c
Hardware watchpoint 3: *0x7fffffffe594
Old value = 2
New value = 3
set (s=0x7fffffffe594, v=3) at test.c:5
5 }
Shell commands
# Run shell commands.
(gdb) shell zcat /proc/config.gz | grep CONFIG_KVM=
CONFIG_KVM=m
# Pipe gdb command to shell command.
(gdb) pipe info proc mapping | grep libc
0x7ffff7a1a000 0x7ffff7a42000 0x28000 0x0 r--p /usr/lib/libc.so.6
0x7ffff7a42000 0x7ffff7b9d000 0x15b000 0x28000 r-xp /usr/lib/libc.so.6
0x7ffff7b9d000 0x7ffff7bf2000 0x55000 0x183000 r--p /usr/lib/libc.so.6
0x7ffff7bf2000 0x7ffff7bf6000 0x4000 0x1d7000 r--p /usr/lib/libc.so.6
0x7ffff7bf6000 0x7ffff7bf8000 0x2000 0x1db000 rw-p /usr/lib/libc.so.6
Know Bugs
Workaround command + finish bug
When using finish inside a command block, commands after finish are not
executed. To workaround that bug one can create a wrapper function which calls
finish.
define handler
bt
finish
info reg rax
end
command
handler
end
Launch debuggee through an exec wrapper
> cat test.c
#include <stdio.h>
#include <stdlib.h>
int main() {
const char* env = getenv("MOOSE");
printf("$MOOSE=%s\n", env ? env : "<nullptr>");
}
> cat test.sh
#!/bin/bash
echo "running test.sh wapper"
export MOOSE=moose
exec ./test
> gcc -g -o test test.c
> gdb test
(gdb) r
$MOOSE=<nullptr>
(gdb) set exec-wrapper bash test.sh
(gdb) r
running test.sh wapper
$MOOSE=moose
gdbserver(1)
CLI
gdbserver [opts] comm prog [args]
opts:
--disable-randomization
--no-disable-randomization
--wrapper W --
comm:
host:port
tty
Example
# Start gdbserver.
gdbserver localhost:1234 /bin/ls
# Attach gdb.
gdb -ex 'target remote localhost:1234'
Wrapper example: Set environment variables just for the debugee
Set env as execution wrapper with some variables.
The wrapper will be executed before the debugee.
gdbserver --wrapper env FOO=123 BAR=321 -- :12345 /bin/ls
Binary
od(1)
od [opts] <file>
-An don't print addr info
-tx4 print hex in 4 byte chunks
-ta print as named character
-tc printable chars or backslash escape
-w4 print 4 bytes per line
-j <n> skip <n> bytes from <file> (hex if start with 0x)
-N <n> dump <n> bytes (hex of start with 0x)
ASCII to hex string
echo -n AAAABBBB | od -An -w4 -tx4
>> 41414141
>> 42424242
echo -n '\x7fELF\n' | od -tx1 -ta -tc
>> 0000000 7f 45 4c 46 0a # tx1
>> del E L F nl # ta
>> 177 E L F \n # tc
Extract parts of file
For example .rodata section from an elf file. We can use readelf to get the
offset into the file where the .rodata section starts.
readelf -W -S foo
>> Section Headers:
>> [Nr] Name Type Address Off Size ES Flg Lk Inf Al
>> ...
>> [15] .rodata PROGBITS 00000000004009c0 0009c0 000030 00 A 0 0 16
With the offset of -j 0x0009c0 we can dump -N 0x30 bytes from the beginning of
the .rodata section as follows:
od -j 0x0009c0 -N 0x30 -tx4 -w4 foo
>> 0004700 00020001
>> 0004704 00000000
>> *
>> 0004740 00000001
>> 0004744 00000002
>> 0004750 00000003
>> 0004754 00000004
Note: Numbers starting with 0x will be interpreted as hex by od.
xxd(1)
xxd [opts]
-p dump continuous hexdump
-r convert hexdump into binary ('revert')
-e dump as little endian mode
-i output as C array
ASCII to hex stream
echo -n 'aabb' | xxd -p
>> 61616262
Hex to binary stream
echo -n '61616262' | xxd -p -r
>> aabb
ASCII to binary
echo -n '\x7fELF' | xxd -p | xxd -p -r | file -p -
>> ELF
ASCII to C array (hex encoded)
xxd -i <(echo -n '\x7fELF')
>> unsigned char _proc_self_fd_11[] = {
>> 0x7f, 0x45, 0x4c, 0x46
>> };
>> unsigned int _proc_self_fd_11_len = 4;
Patching binary file by hand in hex mode
xxd /bin/ls > ls.hex
# edit binary file in hex format (ascii)
xxd -r ls.hex > ls
readelf(1)
readelf [opts] <elf>
-W|--wide wide output, dont break output at 80 chars
-h print ELF header
-S print section headers
-l print program headers + segment mapping
-d print .dynamic section (dynamic link information)
--syms print symbol tables (.symtab .dynsym)
--dyn-syms print dynamic symbol table (exported symbols for dynamic linker)
-r print relocation sections (.rel.*, .rela.*)
objdump(1)
objdump [opts] <elf>
-M intel use intil syntax
-d disassemble text section
-D disassemble all sections
--disassemble=<sym> disassemble symbol <sym>
-S mix disassembly with source code
-C demangle
-j <section> display info for section
--[no-]show-raw-insn [dont] show object code next to disassembly
--visualize-jumps[=color] visualize jumps with ascii art, optionally color arrows
Disassemble section
For example .plt section:
objdump -j .plt -d <elf>
Example: disassemble raw binary
This can be helpful for example as a cheap analysis tool when toying with JIT
generating code. We could just write thee binary code buffer to a file and
disassemble with objdump.
To re-create that case, we just assemble and link some ELF file and then create
a raw binary of the text section with objcopy.
# file: test.s
.section .text, "ax"
.global _start
_start:
xor %rax, %rax
mov $0x8, %rax
1:
cmp $0, %rax
je 2f
dec %rax
jmp 1b
2:
# x86-64 exit(2) syscall
mov $0, %rdi
mov $60, %rax
syscall
# Assemble & link.
as -o test.o test.s
ld -o test test.o testc.o
# ELF -> binary (only take .text section).
objcopy -O binary --only-section .text test test-bin
# Disassemble raw binary.
objdump -D -b binary -m i386:x86-64 test-bin
Example: disassemble specific symbol
# Disassemble main().
objdump --disassemble=main <bin>
# Disassemble 'foo::bar()' (mangled).
objdump --disassemble=_ZN3foo3barEvr <bin>
# Disassemble 'foo::bar()' (demangled), requires -C
objdump -C --disassemble=foo::bar <bin>
nm(1)
nm [opts] <elf>
-C demangle
-u undefined only
Development
c++filt(1)
Demangle symbol
c++-filt [opts] <symbol_str>
-t Try to also demangle types.
Demangle stream
For example dynamic symbol table:
readelf -W --dyn-syms <elf> | c++filt
Demangle types
// file: type.cc
#include <cstdio>
#include <typeinfo>
#define P(ty) printf(#ty " -> %s\n", typeid(ty).name())
template <typename T = void>
struct Foo {};
int main() {
P(int);
P(unsigned char);
P(Foo<>);
P(Foo<int>);
}
Build and run:
$ clang++ type.cc && ./a.out | c++filt
int -> i
unsigned char -> h
Foo<> -> 3FooIvE
Foo<int> -> 3FooIiE
$ clang++ type.cc && ./a.out | c++filt -t
int -> int
unsigned char -> unsigned char
Foo<> -> Foo<void>
Foo<int> -> Foo<int>
c++
openstd cpp standards.
Source files of most examples is available here.
Type deduction
Force compile error to see what auto is deduced to.
auto foo = bar();
// force compile error
typename decltype(foo)::_;
Strict aliasing and type punning
The strict aliasing rules describe via which alias a value can be accessed.
Informal: an
aliasis a reference / pointer to a value.
Accessing a value through an alias that violates the strict aliasing rules is
undefined behavior (UB).
Examples below on godbolt.
int i = 0;
// Valid aliasing (signed / unsigned type).
*reinterpret_cast<signed int*>(&i);
*reinterpret_cast<unsigned int*>(&i);
// Valid aliasing (cv qualified type).
*reinterpret_cast<const int*>(&i);
*reinterpret_cast<const unsigned*>(&i);
// Valid aliasing (byte type).
*reinterpret_cast<char*>(&i);
*reinterpret_cast<std::byte*>(&i);
// Invalid aliasing, dereferencing pointer is UB.
*reinterpret_cast<short*>(&i);
*reinterpret_cast<float*>(&i);
NOTE: Casting pointer to invalid aliasing type is not directly UB, but dereferencing the pointer is UB.
short s[2] = { 1, 2 };
// Invalid aliasing (UB) - type punning, UB to deref ptr (int has stricter
// alignment requirements than short).
*reinterpret_cast<int*>(s);
// Arbitrary byte pointer.
char c[4] = { 1, 2, 3, 4 };
// Invalid aliasing (UB) - type punning, UB to deref ptr (int has stricter
// alignment requirements than char).
*reinterpret_cast<int*>(c);
At the time of writing, the current c++ std draft contains the following.
If a program attempts to access the stored value of an object through a glvalue
whose type is not **similar** (7.3.6) to one of the following types the
behavior is undefined [44]
(11.1) the dynamic type of the object,
(11.2) a type that is the signed or unsigned type corresponding to the dynamic
type of the object, or
(11.3) a char, unsigned char, or std::byte type.
[44]: The intent of this list is to specify those circumstances in which an
object can or cannot be aliased.
The paragraph is short but one also needs to understand the meaning of similar (similar_types).
This paragraph is actually somewhat more explicit in the c++17 std.
If a program attempts to access the stored value of an object through a glvalue
of other than one of the following types the behavior is undefined [63]
(11.1) the dynamic type of the object,
(11.2) a cv-qualified version of the dynamic type of the object,
(11.3) a type similar (as defined in 7.5) to the dynamic type of the object,
(11.4) a type that is the signed or unsigned type corresponding to the dynamic
type of the object,
(11.5) a type that is the signed or unsigned type corresponding to a
cv-qualified version of the dynamic type of the object,
(11.6) an aggregate or union type that includes one of the aforementioned types
among its elements or non- static data members (including, recursively,
an element or non-static data member of a subaggregate or contained
union),
(11.7) a type that is a (possibly cv-qualified) base class type of the dynamic
type of the object,
(11.8) a char, unsigned char, or std::byte type.
[63]: The intent of this list is to specify those circumstances in which an
object may or may not be aliased.
Additional references:
-
What is the Strict Aliasing Rule and Why do we care
The article shows a small example how the compiler may optimized using the strict aliasing rules.
int alias(int* i, char* c) { *i = 1; *c = 'a'; // char* may alias int* return *i; } int noalias(int* i, short* s) { *i = 1; *s = 2; // short* does not alias int* return *i; }alias(int*, char*): mov DWORD PTR [rdi] ,0x1 ; *i = 1; mov BYTE PTR [rsi], 0x61 ; *c = 'a'; mov eax,DWORD PTR [rdi] ; Must reload, char* can alias int*. ret noalias(int*, short*): mov DWORD PTR [rdi], 0x1 ; *i = 1; mov WORD PTR [rsi], 0x2 ; *s = 2; mov eax,0x1 ; Must not reload, short* can not alias int*. ret -
reinterpret_cast type aliasing
- Any object pointer type
T1*can be converted to another object pointer typecv T2*. This is exactly equivalent tostatic_cast<cv T2*>(static_cast<cv void*>(expression))(which implies that if T2's alignment requirement is not stricter than T1's, the value of the pointer does not change and conversion of the resulting pointer back to its original type yields the original value). In any case, the resulting pointer may only be dereferenced safely if allowed by the type aliasing rules (see below).
int I; char* X = reinterpret_cast<char*>(&I); // Valid, char allowed to alias int. *X = 42; int* Y = reinterpret_cast<int*>(X); // Cast back to original type. *Y = 1337; // safe char C[4]; int* P = reinterpret_cast<int*>(C); // Cast is ok, not yet UB. *P = 1337; // UB, violates strict aliasing / alignment rules. // https://stackoverflow.com/questions/52492229/c-byte-array-to-int - Any object pointer type
-
On
gccstrict aliasing is enabled starting with-O2.for i in {0..3} g s; do echo "-O$i $(g++ -Q --help=optimizers -O$i | grep fstrict-aliasing)"; done -O0 -fstrict-aliasing [disabled] -O1 -fstrict-aliasing [disabled] -O2 -fstrict-aliasing [enabled] -O3 -fstrict-aliasing [enabled] -Og -fstrict-aliasing [disabled] -Os -fstrict-aliasing [enabled]
__restrict keyword
The __restrict keyword allows the programmer to tell the compiler that two
pointer will not alias each other.
int alias(int* a, int* b) {
*a = 1;
*b = 2;
return *a;
}
// alias(int*, int*): # @alias(int*, int*)
// mov dword ptr [rdi], 1
// mov dword ptr [rsi], 2
// mov eax, dword ptr [rdi]
// ret
int noalias(int* __restrict a, int* __restrict b) {
*a = 1;
*b = 2;
return *a;
}
// noalias(int*, int*): # @noalias(int*, int*)
// mov dword ptr [rdi], 1
// mov dword ptr [rsi], 2
// mov eax, 1
// ret
However this should only be used with care and in a narrow scope, as it is easy to violate self defined contract, see godbolt.
Type punning
The correct way to do type-punning in c++:
std::bit_cast(c++20)std::memcpy
Variadic templates (parameter pack)
#include <iostream>
// -- Example 1 - print template value arguments.
// Base case with one parameter.
template<int P>
void show_int() {
printf("%d\n", P);
}
// General case with at least two parameters, to disambiguate from base case.
template<int P0, int P1, int... Params>
void show_int() {
printf("%d, ", P0);
show_int<P1, Params...>();
}
// -- Example 2 - print values of different types.
// Base case with one parameter.
template<typename T>
void show(const T& t) {
std::cout << t << '\n';
}
// General case with at least two parameters, to disambiguate from base case.
template<typename T0, typename T1, typename... Types>
void show(const T0& t0, const T1& t1, const Types&... types) {
std::cout << t0 << ", ";
show(t1, types...);
}
int main() {
show_int<1, 2, 3, 4, 5>();
show(1, 1.0, "foo", 'a');
}
Forwarding reference (fwd ref)
A forwarding reference is a special references that preserves the value category of a function parameter and therefore allows for perfect
forwarding.
A forwarding reference is a parameter of a function template, which is declared
as rvalue reference to a non-cv qualified type template parameter.
template<typename T>
void fn(T&& param); // param is a forwarding reference
Perfect forwarding can be achieved with std::forward. This for
example allows a wrapper function to pass a parameter with the exact same
value category to a down-stream function which is being invoked in the wrapper.
#include <cstdio>
#include <utility>
struct M {};
// -- CONSUMER -----------------------------------------------------------------
void use(M&) {
puts(__PRETTY_FUNCTION__);
}
void use(M&&) {
puts(__PRETTY_FUNCTION__);
}
// -- TESTER -------------------------------------------------------------------
template<typename T>
void wrapper(T&& param) { // forwarding reference
puts(__PRETTY_FUNCTION__);
// PARAM is an lvalue, therefore this always calls use(M&).
use(param);
}
template<typename T>
void fwd_wrapper(T&& param) { // forwarding reference
puts(__PRETTY_FUNCTION__);
// PARAM is an lvalue, but std::forward returns PARAM with the same value
// category as the forwarding reference takes.
use(std::forward<T>(param));
}
// -- MAIN ---------------------------------------------------------------------
int main() {
{
std::puts("==> wrapper rvalue reference");
wrapper(M{});
// calls use(M&).
std::puts("==> wrapper lvalue reference");
struct M m;
wrapper(m);
// calls use(M&).
}
{
std::puts("==> fwd_wrapper rvalue reference");
fwd_wrapper(M{});
// calls use(M&&).
std::puts("==> fwd_wrapper lvalue reference");
struct M m;
fwd_wrapper(m);
// calls use(M&).
}
}
Example: any_of template meta function
#include <type_traits>
template<typename T, typename... U>
struct any_of : std::false_type {};
// Found our type T in the list of types U.
template<typename T, typename... U>
struct any_of<T, T, U...> : std::true_type {};
// Pop off the first element in the list of types U,
// since it didn't match our type T.
template<typename T, typename U0, typename... U>
struct any_of<T, U0, U...> : any_of<T, U...> {};
// Convenience template variable to invoke meta function.
template<typename T, typename... U>
constexpr bool any_of_v = any_of<T, U...>::value;
static_assert(any_of_v<int, char, bool, int>, "");
static_assert(!any_of_v<int, char, bool, float>, "");
Example: SFINAE (enable_if)
Provide a single entry point Invoke to call some Operations.
Use enable_if to enable/disable the template functions depending on the two
available traits an operation can have:
- Operation returns a result
- Operation requires a context
#include <iostream>
#include <type_traits>
// Helper meta fns.
template<typename T>
using enable_if_bool = std::enable_if_t<T::value, bool>;
template<typename T>
using disable_if_bool = std::enable_if_t<!T::value, bool>;
template<typename T>
using has_dst = std::integral_constant<bool, !std::is_same<typename T::Return, void>::value>;
// Template meta programming invoke machinery.
namespace impl {
// Invoke an OPERATION which *USES* a context.
template<typename Ctx, template<typename> class Op, typename... P,
enable_if_bool<typename Op<Ctx>::HasCtx> = true>
typename Op<Ctx>::Return Invoke(const Ctx& C, P... params) {
return Op<Ctx>()(C, params...);
}
// Invoke an OPERATION which uses *NO* context.
template<typename Ctx, template<typename> class Op, typename... P,
disable_if_bool<typename Op<Ctx>::HasCtx> = true>
typename Op<Ctx>::Return Invoke(const Ctx&, P... params) {
return Op<Ctx>()(params...);
}
} // namespace impl
// Invoke an OPERATION which *HAS* a DESTINATION with arbitrary number of arguments.
template<typename Ctx, template<typename> class Op, typename... P,
enable_if_bool<has_dst<Op<Ctx>>> = true>
void Invoke(const Ctx& C, P... params) {
std::cout << "Invoke " << Op<Ctx>::Name << '\n';
typename Op<Ctx>::Return R = impl::Invoke<Ctx, Op>(C, params...);
std::cout << "returned -> " << R << '\n';
}
// Invoke an OPERATION which has *NOT* a DESTINATION with arbitrary number of arguments.
template<typename Ctx, template<typename> class Op, typename... P,
disable_if_bool<has_dst<Op<Ctx>>> = true>
void Invoke(const Ctx& C, P... params) {
std::cout << "Invoke " << Op<Ctx>::Name << " without destination." << '\n';
impl::Invoke<Ctx, Op>(C, params...);
}
// Custom context.
struct Ctx {
void out(const char* s, unsigned v) const {
printf("%s%x\n", s, v);
}
};
// Operations to invoke.
template<typename Ctx>
struct OpA {
using HasCtx = std::false_type;
using Return = int;
static constexpr const char* const Name = "OpA";
constexpr Return operator()(int a, int b) const {
return a + b;
}
};
template<typename Ctx>
struct OpB {
using HasCtx = std::true_type;
using Return = void;
static constexpr const char* const Name = "OpB";
Return operator()(const Ctx& C, unsigned a) const {
C.out("a = ", a);
}
};
int main() {
Ctx C;
Invoke<Ctx, OpA>(C, 1, 2);
Invoke<Ctx, OpB>(C, 0xf00du);
return 0;
}
Example: Minimal templatized test registry
A small test function registry bringing together a few different template features.
#include <cstdio>
#include <functional>
#include <map>
#include <string>
#include <type_traits>
template<typename R, typename... P>
struct registry {
using FUNC = R (*)(P...);
using SELF = registry<R, P...>;
using RET = R;
static SELF& get() {
static SELF r;
return r;
}
bool add(std::string nm, FUNC fn) {
const auto r = m_fns.insert({std::move(nm), std::move(fn)});
return r.second;
}
R invoke(const std::string& nm, P... p) const {
return invoke_impl<R>(nm, p...);
}
void dump() const {
for (const auto& it : m_fns) {
std::puts(it.first.c_str());
}
}
private:
std::map<std::string, FUNC> m_fns;
template<typename RET>
std::enable_if_t<std::is_same_v<RET, void>> invoke_impl(const std::string& nm, P... p) const {
const auto it = m_fns.find(nm);
if (it == m_fns.end()) {
return;
}
std::invoke(it->second, p...);
}
template<typename RET>
std::enable_if_t<!std::is_same_v<RET, void>, RET> invoke_impl(const std::string& nm,
P... p) const {
const auto it = m_fns.find(nm);
if (it == m_fns.end()) {
static_assert(std::is_default_constructible_v<RET>,
"RET must be default constructible");
return {};
}
return std::invoke(it->second, p...);
}
};
#define TEST_REGISTER(REGISTRY, NAME) \
static bool regfn_##REGISTRY##NAME() { \
const bool r = REGISTRY::get().add(#NAME, NAME); \
if (!r) { \
std::puts("Failed to register test " #NAME ", same name already registered!"); \
std::abort(); \
} \
return r; \
} \
static const bool reg_##REGISTRY##NAME = regfn_##REGISTRY##NAME();
#define TEST(REGISTRY, NAME, ...) \
REGISTRY::RET NAME(__VA_ARGS__); \
TEST_REGISTER(REGISTRY, NAME); \
REGISTRY::RET NAME(__VA_ARGS__)
// -- Usage 1 simple usage.
using REG1 = registry<void>;
TEST(REG1, test1) {
std::puts("REG1::test1");
}
TEST(REG1, test2) {
std::puts("REG1::test2");
}
// -- Usage 2 with convenience macro wrapper.
using REG2 = registry<void, bool>;
#define TEST2(NAME, ...) TEST(REG2, NAME, ##__VA_ARGS__)
TEST2(test1, bool val) {
printf("REG2::test1 val %d\n", val);
}
int main() {
const auto& R1 = REG1::get();
R1.dump();
R1.invoke("test1");
R1.invoke("test2");
const auto& R2 = REG2::get();
R2.dump();
R2.invoke("test1", true);
return 0;
}
Example: Concepts pre c++20
Prior to c++20's concepts, SFINAE and std::void_t can be leveraged to build
something similar allowing to define an interface (aka trait) for a template
parameter.
template<typename T, template<typename> class Checker, typename = void>
struct is_valid : std::false_type {};
template<typename T, template<typename> class Checker>
struct is_valid<T, Checker, std::void_t<Checker<T>>> : std::true_type {};
template<typename T, template<typename> class Checker>
static constexpr bool is_valid_v = is_valid<T, Checker>::value;
// -----------------------------------------------------------------------------
template<typename T, typename R, template<typename> class Checker, typename = void>
struct is_valid_with_ret : std::false_type {};
template<typename T, typename R, template<typename> class Checker>
struct is_valid_with_ret<T, R, Checker, std::void_t<Checker<T>>> : std::is_same<R, Checker<T>> {};
template<typename T, typename R, template<typename> class Checker>
static constexpr bool is_valid_with_ret_v = is_valid_with_ret<T, R, Checker>::value;
// -----------------------------------------------------------------------------
template<typename T>
struct is_entry {
template<typename TT>
using init = decltype(std::declval<TT>().init());
template<typename TT>
using tag = decltype(std::declval<TT>().tag());
template<typename TT>
using val = decltype(std::declval<TT>().val());
static constexpr bool value = is_valid_v<T, init> && is_valid_with_ret_v<T, int, tag> &&
is_valid_with_ret_v<T, typename T::Type, val>;
};
template<typename T>
static constexpr bool is_entry_v = is_entry<T>::value;
template<typename E>
struct Entry {
using Type = E;
void init();
int tag() const;
E val() const;
};
int main() {
static_assert(is_entry_v<Entry<bool>>, "");
}
The main mechanic can be explained with the following reduced example. If one
of the decltype(std:declval<T>... expressions is ill-formed, the template
specialization for is_valid will be removed from the candidate set due to
SFINAE.
#include <type_traits>
// (1) Primary template.
template<typename T, typename = void>
struct is_valid : std::false_type {};
// (2) Partial template specialization.
template<typename T>
struct is_valid<T, std::void_t<decltype(std::declval<T>().some_fun1()),
decltype(std::declval<T>().some_fun2())>> : std::true_type {};
struct A {
void some_fun1() {}
void some_fun2() {}
};
struct B {};
static_assert(is_valid<A>::value, "is true");
// * Compare template arg list with primary template, we only supplied one
// arg, the second one will be defaulted as
// is_valid<A, void>
// * Compare template arg list against available specializations, this will
// try to match the pattern <A, void> against the patterns defined in the
// partial specializations.
// * Try specialization (2)
// * T -> A
// * Evaluate std::void_t -> decltype's are well-formed
// std::void_t<...> -> void
// * Specialization (2) matches <A, void>
// * Pick the most specialized version -> (2)
static_assert(!is_valid<B>::value, "is false");
// * Compare template arg list with primary template, we only supplied one
// arg, the second one will be defaulted as
// is_valid<A, void>
// * Compare template arg list against available specializations, this will
// try to match the pattern <B, void> against the patterns defined in the
// partial specializations.
// * Try specialization (2)
// * T -> B
// * Evaluate std::void_t -> decltype's are ill-formed
// * Specialization (2) is removed from candidate set, no hard error (SFINAE)
// * No specialization matches, take the primary template.
std::declval<T>()creates an instance of type T in an unevaluated context.
A more detailed description is available in the SO discussion How does
void_t work.
Example: Concepts since c++20
// REQUIRES EXPRESSION
// requires { requirement-seq }
// requires ( parameter-list ) { requirement-seq }
//
// [1] https://en.cppreference.com/w/cpp/language/requires
// [2] https://en.cppreference.com/w/cpp/language/constraints#Constraints
//
// REQUIREMENT CLAUSE
// Not the same as a REQUIREMENT EXPRESSIONS, and is used to require
// constraints (express concept bounds).
//
// [1] https://en.cppreference.com/w/cpp/language/constraints#Requires_clauses
// -- HELPER -------------------------------------------------------------------
template<typename T>
using Alias = T;
void print(int);
// -- CONCEPTS & REQUIRE EXPRESSIONS -------------------------------------------
// Simple concept from a type trait.
template<typename T, typename U>
concept Same = std::is_same<T, U>::value;
// Simple requirement concepts.
template<typename T>
concept TraitAddAndPrint = requires(T t, int i) {
// Adding T + int must be supported.
t + i;
// Calling print(T) must be available.
print(t);
};
// Type requirement concepts.
template<typename T>
concept TraitTypes = requires(T t) {
// T must have a type definition inner.
typename T::inner;
// Type alias must exist.
typename Alias<T>;
};
// Compound requirement concepts.
template<typename T>
concept TraitFns = requires(T t, const T c) {
// void T::foo() must exist.
{ t.foo() };
// bool T::bar() const; must exist.
{ c.bar() } -> Same<bool>;
// static void T::stat(); must exist.
{ T::stat() } -> Same<int>;
};
// Nested requirement concepts.
template<typename T>
concept TraitNested = requires(T t) {
// Must satisfy other concepts.
requires TraitTypes<T>;
requires TraitFns<T>;
};
// -- REQUIRE EXPRESSIONS ------------------------------------------------------
// Require expressions can be evaluated to booleans.
template<typename T>
static constexpr bool IsTraitFns = requires { requires TraitFns<T>; };
// Require expressions can also be used in static assertions.
static_assert(requires { requires Same<int, int>; });
static_assert(!requires {
typename Alias<int>;
requires Same<int, void>;
});
// -- TESTS --------------------------------------------------------------------
static_assert(requires { requires TraitAddAndPrint<int>; });
struct FnTypeGood {
using inner = int;
};
struct FnTypeBad {};
static_assert(requires { requires TraitTypes<FnTypeGood>; });
static_assert(!requires { requires TraitTypes<FnTypeBad>; });
struct FnGood {
void foo();
bool bar() const;
static int stat();
};
struct FnBad {};
static_assert(requires { requires TraitFns<FnGood>; });
static_assert(!requires { requires TraitFns<FnBad>; });
struct NestedGood : FnTypeGood, FnGood {};
struct NestedBad1 : FnGood {};
struct NestedBad2 : FnTypeGood {};
static_assert(requires { requires TraitNested<NestedGood>; });
static_assert(!requires { requires TraitNested<NestedBad1>; });
static_assert(!requires { requires TraitNested<NestedBad2>; });
Template selection with partially / fully specializations.
enum Kind {
kPrimary,
kTT,
kIntBool,
kIntInt,
};
// (1) Primary template.
template<typename T, typename U = bool>
struct pair {
static constexpr Kind kind = kPrimary;
};
// (2) Partial template specialization.
template<typename T>
struct pair<T, T> {
static constexpr Kind kind = kTT;
};
// (3) Template specialization.
template<>
struct pair<int, bool> {
static constexpr Kind kind = kIntBool;
};
// (4) Template specialization.
template<>
struct pair<int, int> {
static constexpr Kind kind = kIntInt;
};
int main() {
static_assert(pair<int>::kind == kIntBool, "");
// * Compare template arg list with primary template, we only supplied one
// arg, the second one will be defaulted as
// pair<int, bool>
// * Compare template arg list against available specializations, this will
// try to match the pattern <int, bool> against the patterns defined in the
// partial specializations.
// * (2) <int, bool> pattern does not match
// * (3) <int, bool> pattern does match
// * (4) <int, bool> pattern does not match
// * Pick the most specialized version -> (3)
static_assert(pair<char, char>::kind == kTT, "");
// * Compare template arg list against available specializations, this will
// try to match the pattern <char, char> against the patterns defined in the
// partial specializations.
// * (2) <char, char> pattern does match
// * (3) <char, char> pattern does not match
// * (4) <char, char> pattern does not match
// * Pick the most specialized version -> (2)
static_assert(pair<int, int>::kind == kIntInt, "");
// * Compare template arg list against available specializations, this will
// try to match the pattern <int, int> against the patterns defined in the
// partial specializations.
// * (2) <int, int> pattern does match
// * (3) <int, int> pattern does match
// * (4) <int, int> pattern does not match
// * Pick the most specialized version -> (3)
static_assert(pair<char, short>::kind == kPrimary, "");
// * Compare template arg list against available specializations, this will
// try to match the pattern <char, short> against the patterns defined in the
// partial specializations.
// * (2) <char, short> pattern does not match
// * (3) <char, short> pattern does not match
// * (4) <char, short> pattern does not match
// * No specialization matches, take the primary template.
}
Example: Perfect forwarding
#include <cassert>
#include <cstdio>
#include <new>
#include <type_traits>
#include <utility>
struct S {};
struct M {
M() {
std::puts("M()");
}
M(const M&) {
std::puts("M(M&)");
}
M(M&&) {
std::puts("M(M&&)");
}
M& operator=(const M&) = delete;
M& operator=(M&&) = delete;
M(S&, int) {
std::puts("M(S&)");
}
M(S&&, int) {
std::puts("M(S&&)");
}
~M() {
std::puts("~M()");
}
};
template<typename T>
struct option {
static_assert(!std::is_reference_v<T>);
constexpr option() = default;
template<typename... Params>
constexpr option(Params&&... params) : m_has_val(true) {
// BAD: does not perfectly forward!
// eg, if option(S&&) is invoked, this would invoke M(S&).
// new (&m_val) T(params...);
// GOOD: perfectly forwards params to constructor of T.
new (m_val) T(std::forward<Params>(params)...);
}
~option() {
reset();
}
constexpr T& value() {
assert(m_has_val);
// Placement new starts a new lifetime, launder pointer returned to the
// aligned storage.
//
// [1] https://en.cppreference.com/w/cpp/utility/launder
return *__builtin_launder(reinterpret_cast<T*>(m_val));
}
private:
constexpr void reset() {
if (!m_has_val) {
return;
}
if constexpr (!std::is_trivially_destructible_v<T>) {
value().~T();
};
}
alignas(T) char m_val[sizeof(T)];
bool m_has_val{false};
};
int main() {
std::puts("==> case 1");
// invokes M(S&&, int)
option<M> opt1(S{}, 123);
std::puts("==> case 2");
// invokes M() + M(M&&)
option<M> x /* option(M&&) + M(M&&) */ = M{} /* M() */;
}
glibc
malloc tracer mtrace(3)
Trace memory allocation and de-allocation to detect memory leaks.
Need to call mtrace(3) to install the tracing hooks.
If we can't modify the binary to call mtrace we can create a small shared
library and pre-load it.
// libmtrace.c
#include <mcheck.h>
__attribute__((constructor)) static void init_mtrace() { mtrace(); }
Compile as:
gcc -shared -fPIC -o libmtrace.so libmtrace.c
To generate the trace file run:
export MALLOC_TRACE=<file>
LD_PRELOAD=./libmtrace.so <binary>
Note: If MALLOC_TRACE is not set mtrace won't install tracing hooks.
To get the results of the trace file:
mtrace <binary> $MALLOC_TRACE
malloc check mallopt(3)
Configure action when glibc detects memory error.
export MALLOC_CHECK_=<N>
Useful values:
1 print detailed error & continue
3 print detailed error + stack trace + memory mappings & abort
7 print simple error message + stack trace + memory mappings & abort
gcc(1)
CLI
-vverbose, outputs exact compiler/linker invocations made by the gcc driver-###dry-run, outputting exact compiler/linker invocations-print-multi-libprint available multilib configurations--help=<class>print description of cmdline options for given class, egwarnings,optimizers,target,c,c++-Wl,<opt>additional option passed to the linker invocation (can be specified multiple times)-Wl,--tracetrace each file the linker touches
Preprocessing
While debugging can be helpful to just pre-process files.
gcc -E [-dM] ...
-Erun only preprocessor-dMlist only#definestatements
Target options
# List all target options with their description.
gcc --help=target
# Configure for current cpu arch and query (-Q) value of options.
gcc -march=native -Q --help=target
Warnings / optimizations
# List available warnings with short description.
gcc --help=warnings
# List available optimizations with short description.
gcc --help=optimizers
# Prepend --help with `-Q` to print wheter options are enabled or disabled
# instead showing their description.
Sanitizer
# Enable address sanitizer, a memory error checker (out of bounds, use after free, ..).
gcc -fsanitize=address ...
# Enable leak sanitizer, a memory leak detector.
gcc -fsanitize=leak
# Enable undefined behavior sanitizer, detects various UBs (integer overflow, ..).
gcc -fsanitize=undefined ...
# Enable thread sanitizer, a data race detector.
gcc -fsanitize=thread
Builtins
__builtin_expect(expr, cond)
Give the compiler a hint which branch is hot, so it can lay out the code accordingly to reduce number of jump instructions. See on compiler explorer.
The semantics of this hint are as follows, the compiler prioritises expr == cond. So __builtin_expect(expr, 0) means that we expect the expr to be 0
most of the time.
echo "
extern void foo();
extern void bar();
void run0(int x) {
if (__builtin_expect(x,0)) { foo(); }
else { bar(); }
}
void run1(int x) {
if (__builtin_expect(x,1)) { foo(); }
else { bar(); }
}
" | gcc -O2 -S -masm=intel -o /dev/stdout -xc -
Will generate something similar to the following.
run0:baris on the path without branchrun1:foois on the path without branch
run0:
test edi, edi
jne .L4
xor eax, eax
jmp bar
.L4:
xor eax, eax
jmp foo
run1:
test edi, edi
je .L6
xor eax, eax
jmp foo
.L6:
xor eax, eax
jmp bar
ABI (Linux)
- C ABI (x86_64) - SystemV ABI
- C++ ABI - C++ Itanium ABI
gas
Frequently used directives
.sectionto define a section (elf files).section .text.foo, "ax", @progbits ; defines section named .text.foo with alloc+exec perms .section .data.foo, "aw", @progbits ; defines section named .data.foo with alloc+write perms .section .rodata.foo, "a", @progbits ; defines section named .rodata.foo with alloc perms.byte,.2byte,.4byte,.8byteto define a N byte value.byte 0xaa .2byte 0xaabb # .word .2byte 0xaa, 0xbb .4byte 0xaabbccdd # .long .8byte 0xaabbccdd11223344 # .quad.asciito define an ascii string.ascii "foo" ; allocates 3 bytes.ascizto define an ascii string with'\0'terminator.asciz "foo" ; allocates 4 bytes (str + \0).macroto define assembler macros. Arguments are accessed with the\argsyntax..macro defstr name str \name: .ascii "\str" \name\()_len: .8byte . - \name .endm ; use as defstr foo, "foobar"Use
\()to concatenate macro argument and literal..reptto repeat a sequence of lines between.reptand.endr..rept 4 .4byte 123 .endr.fill cnt, elem_size, valwritecnttimesvalwith element sizeelem_size. For example one can use it to create a mbr boot record (magic number 0xaa55 at byte 511, 512)..section .boot, "ax", @progbits ; some code .. .4byte 0xff .fill 510 - (. - .boot), 1, 0x00 .2byte 0xaa55 ; as foo.s && objdump -j .boot -s ; Contents of section .boot: ; 0000 ff000000 00000000 00000000 00000000 ; .. ; 01f0 00000000 00000000 00000000 000055aaHere
.stands for the current location counter.
References
ld(1)
ld [opts] files...
-T <script> use <script> as linker script
--trace report each file the linker touches
--start-group archives --end-group
search archives repearepeatedly until no new
undefined references are created
(eg helpfull with list of static libraries)
Linker Script
output sections are defined as follows (full description at output
section and input section).
section_name [vaddr] : [AT(paddr)] {
file_pattern (section_pattern)
}
The following gives an example of an output section with two input section rules.
.foo : {
abc.o (.foo)
*.o (.foo.*)
}
Example: virtual vs physical (load) address
Sometimes code is initially located at a different location as when being run. For example in embedded cases, where code may initially resides in a rom and startup code will copy a section with writable data into ram. Code accessing the writable data accesses the data in the ram.
In this case we need different addresses for the same data.
- The
virtualor runtime address, this is the address used when the linker resolves accesses to the data. Hence, this is the address the data will have when the code is running. - The
physicalor load address, this is the address the data is stored at initially. Startup code typically copies the initial values from thephysicalto thevirtualaddress.
The following shows an example linker script which uses virtual and physical addresses. The full source files can be found here.
OUTPUT_FORMAT(elf64-x86-64)
ENTRY(_entry)
SECTIONS {
/* Set the initial location counter (vaddr) */
. = 0x00800000;
/* Create .text output section at current vaddr */
.text : {
*(.text*)
}
ASSERT(. == 0x00800000 + SIZEOF(.text), "inc loc counter automatically")
/* Create .data section at location counter aligned to the next 0x100 (vaddr) */
/* Set the load address to 0x00100000 (paddr) */
.data ALIGN(0x100) : AT(0x00100000) {
HIDDEN(_data_vaddr = .);
HIDDEN(_data_paddr = LOADADDR(.data));
*(.data*)
}
/* Create .rodata with explicit vaddr */
/* Re-adjust the paddr location counter */
.rodata 0x00804000 : AT(ADDR(.rodata)) {
*(.rodata*)
}
ASSERT(. == 0x00804000 + SIZEOF(.rodata), "inc loc counter automatically")
.stack ALIGN (0x1000) : {
. += 0x1000;
HIDDEN(_stack_top = .);
}
/DISCARD/ : {
*(.*)
}
}
/* Some example assertions */
ASSERT(ADDR(.data) != LOADADDR(.data), "DATA vaddr and paddr must be different")
ASSERT(SIZEOF(.stack) == 0x1000, "STACK section must be 0x1000")
We can use the following assembly snippet to explore the linker script.
.section .text, "ax", @progbits
.global _entry
_entry:
mov $_stack_top, %rsp
mov $asm_array, %rax
mov (asm_len), %eax
hlt
jmp _entry
.section .data.asm, "aw", @progbits
asm_array:
.4byte 0xa
.4byte 0xb
.4byte 0xc
.4byte 0xd
.rept 4
.4byte 0xff
.endr
.section .rodata.asm, "a", @progbits
asm_len:
.4byte 8
gcc -c data.S && ld -o link-nomem -T link-nomem.ld data.o
The elf load segments show the difference in physical and virtual address
for the segment containing the .data section.
> readelf -W -l link-nomem
# There are 4 program headers, starting at offset 64
#
# Program Headers:
# Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
# LOAD 0x001100 0x0000000000800100 0x0000000000100000 0x000020 0x000020 RW 0x1000
# LOAD 0x002000 0x0000000000800000 0x0000000000800000 0x000018 0x000018 R E 0x1000
# LOAD 0x003000 0x0000000000804000 0x0000000000804000 0x000004 0x000004 R 0x1000
# LOAD 0x000000 0x0000000000805000 0x0000000000805000 0x000000 0x001000 RW 0x1000
#
# Section to Segment mapping:
# Segment Sections...
# 00 .data
# 01 .text
# 02 .rodata
# 03 .stack
Startup code could copy data from _data_paddr to _data_vaddr.
> nm link-nomem
# 0000000000800100 d asm_array
# 0000000000804000 r asm_len
# 0000000000100000 a _data_paddr
# 0000000000800100 d _data_vaddr
# 0000000000800000 T _entry
# 0000000000806000 b _stack_top
The linker resolves symbols to their virtual address, this can be seen by the
access to the asm_array variable.
> objdump -d link-nomem
# Disassembly of section .text:
#
# 0000000000800000 <_entry>:
# 800000: 48 c7 c4 00 60 80 00 mov $0x806000,%rsp
# 800007: 48 c7 c0 00 01 80 00 mov $0x800100,%rax ;; mov $asm_array, %rax
# 80000e: 8b 04 25 00 40 80 00 mov 0x804000,%eax
# 800015: f4 hlt
# 800016: eb e8 jmp 800000 <_entry>
The following linker script shows an example with the MEMORY command.
OUTPUT_FORMAT(elf64-x86-64)
ENTRY(_entry)
MEMORY {
ROM : ORIGIN = 0x00100000, LENGTH = 0x4000
RAM : ORIGIN = 0x00800000, LENGTH = 0x4000
}
SECTIONS {
/* Create .text output section at ROM (vaddr) */
.text : {
*(.text*)
} > ROM
ASSERT(. == ORIGIN(ROM) + SIZEOF(.text), "inc loc counter automatically")
/* Create .data output section at RAM (vaddr) */
/* Set load addr to ROM, right after .text (paddr) */
.data : {
HIDDEN(_data_vaddr = .);
HIDDEN(_data_paddr = LOADADDR(.data));
*(.data*)
} > RAM AT > ROM
/* Append .rodata output section at ROM (vaddr) */
.rodata : {
*(.rodata*)
} > ROM
/* Append .stack output section at RAM (vaddr) aligned up to next 0x1000 */
.stack : ALIGN (0x1000) {
. += 0x1000;
HIDDEN(_stack_top = .);
} > RAM
/DISCARD/ : {
*(.*)
}
}
/* Some example assertions */
ASSERT(ADDR(.data) != LOADADDR(.data), "DATA vaddr and paddr must be different")
ASSERT(ADDR(.rodata) == LOADADDR(.rodata), "RODATA vaddr and paddr must be euqal")
ASSERT(ADDR(.stack) == ORIGIN(RAM) + 0x1000, "STACK section must aligned to 0x1000")
ASSERT(SIZEOF(.stack) == 0x1000, "STACK section must be 0x1000")
References
git(1)
Working areas
+-------------------+ --- stash -----> +-------+
| working directory | | stash | // Shelving area.
| (worktree) | <-- stash pop -- +-------+
+-------------------+
| ^
add |
| reset
v |
+-------------------+
| staging area |
| (index) |
+-------------------+
|
commit
|
v
+-------------------+
| local repository |
+-------------------+
| ^
push |
| fetch /
| pull
v |
+-------------------+
| remote repository |
+-------------------+
Config
git config --list --show-origin ..... list currently set configs and where
they are coming from
git --edit [--global] ............... open config in editor (local or global)
Clean
git clean -X ......... remove only ignored files (-n for dry run)
git clean -f -d -x ... remove untracked & ignored files / folders
git clean -e <pat> ... exclude pattern from deletion
Staging
git add -p [<file>] ............ partial staging (interactive)
Remote
git remote -v .................. list remotes verbose (with URLs)
git remote show [-n] <remote> .. list info for <remote> (like remote HEAD,
remote branches, tracking mapping)
Branching
git branch [-a] ................ list available branches; -a to include
remote branches
git branch -vv ................. list branch & annotate with head sha1 &
remote tracking branch
git branch <bname> ............. create local branch with name <bname>
git branch -d <bname> .......... delete local branch with name <bname>
git checkout <bname> ........... switch to branch with name <bname>
git checkout --track <branch> .. start to locally track a remote branch
git branch --unset-upstream .... unset remote tracking branch
# Remote
git push -u origin <rbname> ........ push local branch to origin (or other
remote), and setup <rbname> as tracking
branch
git push origin --delete <rbname> .. delete branch <rbname> from origin (or
other remote)
Update local from remote
git fetch --prune .................. update all remote references and
remove delete non-existing ones
(does not merge into local tracking branch)
git pull [--rebase] ................ fetch remote references and merge into
local tracking branch (fast-forward by default).
Optionally rebase local tracking branch
on-top of remote branch (in case local
branch has additional commits compared to remote branch).
Tags
git tag -a <tname> -m "descr" ........ creates an annotated tag (full object
containing tagger, date, ...)
git tag -l ........................... list available tags
git checkout tag/<tname> ............. checkout specific tag
git checkout tag/<tname> -b <bname> .. checkout specific tag in a new branch
# Remote
git push origin --tags .... push local tags to origin (or other remote)
Merging
git merge [opt] <commit> .... integrate changes from <commit> since
opt: current branch and <commit> diverged
--squash ................ merge all commits into a single one
--no-commit ............. dont generate commit if the merge succeeds
git merge-base <commit> <commit>
get the common ancestor, since both commits diverged
git rebase -i <upstream> .... interactively rebase on <upstream>, also supports actions
like squashing, editing, rewording, etc of commits
git cherry-pick <commit> .... apply commit on current branch
Worktree
Worktrees allow to maintain multiple working trees in the filesystem linked to the same repository (shared .git folder).
git worktree add <path> .............. create a tree at <path> with a new branch
checked out (bname is basename of <path>)
git worktree add <path> <bname> ...... create a tree at <path> from existing <bname>
git worktree list .................... list existing work trees
git worktree remove <tree> ........... remove work tree
git worktree prune ................... remove stale bookkeeping files
Log & Commit History
git log --oneline ......... shows log in single line per commit -> alias for
'--pretty=oneline --abbrev-commit'
git log --graph ........... text based graph of commit history
git log --decorate ........ decorate log with REFs
git log -p <file> ......... show commit history + diffs for <file>
git log --oneline <file> .. show commit history for <file> in compact format
git log -nN ............... show last N history entries
Diff & Commit Info
git diff <commit>..<commit> [<file>] .... show changes between two arbitrary
commits. If one <commit> is omitted
it is if HEAD is specified.
git diff --name-only <commit>..<commit> . show names of files changed
git diff -U$(wc -l <file>) <file> ....... shows complete file with diffs
instead of usual diff snippets
git diff --staged ....................... show diffs of staged files
git show --stat <commit> ................ show files changed by <commit>
git show <commit> [<file>] .............. show diffs for <commit>
git show <commit>:<file> ................ show <file> at <commit>
Patching
git format-patch <opt> <since>/<revision range>
opt:
-N ................... use [PATCH] instead [PATCH n/m] in subject when
generating patch description (for patches spanning
multiple commits)
--start-number <n> ... start output file generation with <n> as start
number instead '1'
since spcifier:
-3 .................. e.g: create a patch from last three commits
<commit hash> ....... create patch with commits starting after <commit hash>
git am <patch> ......... apply patch and create a commit for it
git apply --stat <PATCH> ... see which files the patch would change
git apply --check <PATCH> .. see if the patch can be applied cleanly
git apply [-3] <PATCH> ..... apply the patch locally without creating a commit,
if the patch does not cleanly apply -3 allows for
a 3-way merge
# eg: generate patches for each commit from initial commit on
git format-patch -N $(git rev-list --max-parents=0 HEAD)
# generate single patch file from a certain commit/ref
git format-patch <COMMIT/REF> --stdout > my-patch.patch
Resetting
git reset [opt] <ref|commit>
opt:
--mixed .................... resets index, but not working tree
--hard ..................... matches the working tree and index to that
of the tree being switched to any changes to
tracked files in the working tree since
<commit> are lost
git reset HEAD <file> .......... remove file from staging
git reset --soft HEAD~1 ........ delete most recent commit; dont revert index & worktree
git reset --mixed HEAD~1 ....... delete most recent commit; revert index; dont revert worktree
git reset --hard HEAD~1 ........ delete most recent commit; revert index & worktree
Assuming an initial history A - B - C - D where HEAD currently points at
D, the different reset operations work as shown below.
Soft reset.
git reset --soft HEAD~2
history: A - B
^HEAD
-> local history is reverted, HEAD moved to B.
-> changes from C + D are still in the worktree & index (appear as staged changes).
Mixed reset.
git reset --mixed HEAD~2
history: A - B
^HEAD
-> local history is reverted, HEAD moved to B.
-> changed from C + D are reverted in the index.
-> changes from C + D are still in the worktree (appear as unstaged changes).
Hard reset.
git reset --head HEAD~2
history: A - B
^HEAD
-> local history is reverted, HEAD moved to B.
-> changes from C + D also reverted in the worktree & index (no pending changes).
Submodules
git submodule add <url> [<path>] .......... add new submodule to current project
git clone --recursive <url> ............... clone project and recursively all
submodules (same as using
'git submodule update --init
--recursive' after clone)
git submodule update --init --recursive ... checkout submodules recursively
using the commit listed in the
super-project (in detached HEAD)
git submodule update --remote <submod> .... fetch & merge remote changes for
<submod>, this will pull
origin/HEAD or a branch specified
for the submodule
git diff --submodule ...................... show commits that are part of the
submodule diff
Bisect
git bisect start BAD GOOD ........ start bisect process in range BAD..GOOD commits
git bisect good .................. mark current commit as good
git bisect bad ................... mark current commit as bad
# Automate bisecting.
git bisect run <script> <args> ... run script to automate bisect process
exit 0 - mark commit as good
exit 1 - mark commit as bad
exit 125 - skip commit (eg doesn't build)
Inspection
git ls-tree [-r] <ref> .... show git tree for <ref>, -r to recursively ls sub-trees
git show <obj> ............ show <obj>
git cat-file -p <obj> ..... print content of <obj>
Revision Specifier
HEAD ........ last commit
HEAD~1 ...... last commit-1
HEAD~N ...... last commit-N (linear backwards when in tree structure, check
difference between HEAD^ and HEAD~)
git rev-list --max-parents=0 HEAD ........... first commit
cmake(1)
Frequently used variables
# Install location.
CMAKE_INSTALL_PREFIX=<path>
# Generate compile_commands.json?
CMAKE_EXPORT_COMPILE_COMMANDS={0,1}
# Project build type.
CMAKE_BUILD_TYPE={Debug, Release, RelWithDebInfo, MinSizeRel}
# C++ standard.
CMAKE_CXX_STANDARD={14,17,..}
PRIVATE / PUBLIC / INTERFACE
These modifier control where properties for a given target are visible.
PRIVATE: Only for the target itself.INTERFACE: Only for anyone linking against the target.PUBLIC: For the target itself and anyone linking against it (effectivelyPRIVATE+INTERFACE).
The following gives an example for preprocessor definitions specified on a library target. This behaves in the same way for other properties like for example include directories.
# CMakeLists.txt
cmake_minimum_required(VERSION 3.14)
project(moose)
# -- LIBRARY
add_library(liba STATIC liba.cc)
target_compile_definitions(liba PUBLIC DEF_PUBLIC)
target_compile_definitions(liba PRIVATE DEF_PRIVATE)
target_compile_definitions(liba INTERFACE DEF_INTERFACE)
# -- APPLICATION
add_executable(main main.cc)
target_link_libraries(main liba)
> touch liba.cc; echo "int main() {}" > main.cc
> cmake -B build -S . -G Ninja
> ninja -C build -j1 --verbose
[1/4] /usr/bin/c++ -DDEF_PRIVATE -DDEF_PUBLIC [..] .../liba.cc
[2/4] [..]
[3/4] /usr/bin/c++ -DDEF_INTERFACE -DDEF_PUBLIC [..] .../main.cc
[4/4] [..]
find_package [ref]
A small example to play with can be found in cmake/module.
find_package(Name MODULE)
Looks for FindName.cmake in paths given by CMAKE_MODULE_PATH and then builtin paths.
find_package(Name CONFIG)
Looks for name-config.cmake or NameConfig.cmake in paths given by
CMAKE_PREFIX_PATH, or path given by Name_DIR and then builtin paths.
make(1)
Anatomy of make rules
target .. : prerequisite ..
recipe
..
target: an output generated by the ruleprerequisite: an input that is used to generate the targetrecipe: list of actions to generate the output from the input
Use
make -pto print all rules and variables (implicitly + explicitly defined).
Pattern rules & variables
Pattern rules
A pattern rule contains the % char (exactly one of them) and look like this example:
%.o : %.c
$(CC) -c $(CFLAGS) $(CPPFLAGS) $< -o $@
The target matches files of the pattern %.o, where % matches any none-empty
substring and other character match just them self.
The substring matched by % is called the stem.
% in the prerequisite stands for the matched stem in the target.
Automatic variables
As targets and prerequisites in pattern rules can't be spelled explicitly in the recipe, make provides a set of automatic variables to work with:
$@: Name of the target that triggered the rule.$<: Name of the first prerequisite.$^: Names of all prerequisites (without duplicates).$+: Names of all prerequisites (with duplicates).$*: Stem of the pattern rule.
# file: Makefile
all: foobar blabla
foo% bla%: aaa bbb bbb
@echo "@ = $@"
@echo "< = $<"
@echo "^ = $^"
@echo "+ = $+"
@echo "* = $*"
@echo "----"
aaa:
bbb:
Running above Makefile gives:
@ = foobar
< = aaa
^ = aaa bbb
+ = aaa bbb bbb
* = bar
----
@ = blabla
< = aaa
^ = aaa bbb
+ = aaa bbb bbb
* = bla
----
Variables related to filesystem paths:
$(CURDIR): Path of current working dir after usingmake -C path
Multi-line variables
define my_var
@echo foo
@echo bar
endef
all:
$(my_var)
Running above Makefile gives:
foo
bar
Arguments
Arguments specified on the command line override ordinary variable assignments in the makefile (overriding variables).
VAR = abc
all:
@echo VAR=$(VAR)
# make
VAR=abc
# make VAR=123
VAR=123
Useful functions
Substitution references
Substitute strings matching pattern in a list.
in := a.o l.a c.o
out := $(in:.o=.c)
# => out = a.c l.a c.c
patsubst (ref)
in := a.c b.c
out := $(patsubst %.c, build/%.o, $(in))
# => out = build/a.o build/b.o
# This is actually equivalent to $(in:%.c=build/%.o)
filter
Keep strings matching a pattern in a list.
in := a.a b.b c.c d.d
out := $(filter %.b %.c, $(in))
# => out = b.b c.c
filter-out
Remove strings matching a pattern from a list.
in := a.a b.b c.c d.d
out := $(filter-out %.b %.c, $(in))
# => out = a.a d.d
abspath
Resolve each file name as absolute path (don't resolve symlinks).
$(abspath fname1 fname2 ..)
realpath
Resolve each file name as canonical path.
$(realpath fname1 fname2 ..)
call (ref)
Invoke parametrized function, which is an expression saved in a variable.
swap = $(2) $(1)
all:
@echo "call swap first second -> $(call swap,first,second)"
Outputs:
call swap first second -> second first
eval (ref)
Allows to define new makefile constructs by evaluating the result of a variable or function.
define new_rule
$(1):
@echo "$(1) -> $(2)"
endef
default: rule1 rule2
$(eval $(call new_rule,rule1,foo))
$(eval $(call new_rule,rule2,bar))
Outputs:
rule1 -> foo
rule2 -> bar
foreach (ref)
Repeat a piece of text for a list of values, given the syntax $(foreach var,list,text).
myfn = x$(1)x
default:
@echo $(foreach V,foo bar baz,$(call myfn,$(V)))
Outputs:
xfoox xbarx xbazx
Examples
Config based settings
conf-y := default
conf-$(FOO) := $(conf-y) foo
conf-$(BAR) := $(conf-y) bar
libs-y := libdef
libs-$(FOO) += libfoo
libs-$(BAR) += libbar
all:
@echo "conf-y: $(conf-y)"
@echo "libs-y: $(libs-y)"
Yields the following results.
$ make
conf-y: default
libs-y: libdef
$ make FOO=y
conf-y: default foo
libs-y: libdef libfoo
$ make BAR=y
conf-y: default bar
libs-y: libdef libbar
$ make FOO=y BAR=y
conf-y: default foo bar
libs-y: libdef libfoo libbar
Using foreach / eval / call to generate new rules
define new_rule
$(1):
@echo "$(1) -> $(2)"
endef
arg-rule1 = foo
arg-rule2 = bar
RULES = rule1 rule2
all: $(RULES)
$(foreach R,$(RULES),$(eval $(call new_rule,$(R),$(arg-$(R)))))
# equivalent to
# $(eval $(call new_rule,rule1,foo))
# $(eval $(call new_rule,rule2,bar))
Outputs:
rule1 -> foo
rule2 -> bar
Use
make -R -pto print the make database including the rules.
ld.so(8)
Environment Variables
LD_PRELOAD=<l_so> colon separated list of libso's to be pre loaded
LD_DEBUG=<opts> comma separated list of debug options
=help list available options
=libs show library search path
=files processing of input files
=symbols show search path for symbol lookup
=bindings show against which definition a symbol is bound
LD_LIBRARY_PATH and dlopen(3)
When dynamically loading a shared library during program runtime with
dlopen(3), only the LD_LIBRARY_PATH as it was during program startup is
evaluated.
Therefore the following is a code smell:
// at startup LD_LIBRARY_PATH=/moose
// Assume /foo/libbar.so
setenv("LD_LIBRARY_PATH", "/foo", true /* overwrite */);
// Will look in /moose and NOT in /foo.
dlopen("libbar.so", RTLD_LAZY);
LD_PRELOAD: Initialization Order and Link Map
Libraries specified in LD_PRELOAD are loaded from left-to-right but
initialized from right-to-left.
> ldd ./main
>> libc.so.6 => /usr/lib/libc.so.6
> LD_PRELOAD=liba.so:libb.so ./main
-->
preloaded in this order
<--
initialized in this order
The preload order determines:
- the order libraries are inserted into the
link map - the initialization order for libraries
For the example listed above the resulting link map will look like the
following:
+------+ +------+ +------+ +------+
| main | -> | liba | -> | libb | -> | libc |
+------+ +------+ +------+ +------+
This can be seen when running with LD_DEBUG=files:
> LD_DEBUG=files LD_PRELOAD=liba.so:libb.so ./main
# load order (-> determines link map)
>> file=liba.so [0]; generating link map
>> file=libb.so [0]; generating link map
>> file=libc.so.6 [0]; generating link map
# init order
>> calling init: /usr/lib/libc.so.6
>> calling init: <path>/libb.so
>> calling init: <path>/liba.so
>> initialize program: ./main
To verify the link map order we let ld.so resolve the memcpy(3) libc
symbol (used in main) dynamically, while enabling LD_DEBUG=symbols,bindings
to see the resolving in action.
> LD_DEBUG=symbols,bindings LD_PRELOAD=liba.so:libb.so ./main
>> symbol=memcpy; lookup in file=./main [0]
>> symbol=memcpy; lookup in file=<path>/liba.so [0]
>> symbol=memcpy; lookup in file=<path>/libb.so [0]
>> symbol=memcpy; lookup in file=/usr/lib/libc.so.6 [0]
>> binding file ./main [0] to /usr/lib/libc.so.6 [0]: normal symbol `memcpy' [GLIBC_2.14]
RTLD_LOCAL and RTLD_DEEPBIND
As shown in the LD_PRELOAD section above, when the dynamic linker resolves
symbol relocations, it walks the link map and until the first object provides
the requested symbol.
When libraries are loaded dynamically during runtime with dlopen(3), one can
control the visibility of the symbols for the loaded library. The following two
flags control this visibility.
RTLD_LOCALthe symbols of the library (and its dependencies) are not visible in the global symbol scope and therefore do not participate in global symbol resolution from other libraries (default).RTLD_GLOBALthe symbols of the library are visible in the global symbol scope.
Additionally to the visibility one can use the RTLD_DEEPBIND flag to define
the lookup order when resolving symbols of the loaded library. With deep
binding, the symbols of the loaded library (and its dependencies) are searched
first before the global scope is searched. Without deep binding, the order is
reversed and the global space is searched first, which is the default.
The sources in ldso/deepbind give a minimal example, which can be used to experiment with the different flags and investigate their behavior.
main
|-> explicitly link against liblink.so
|-> dlopen(libdeep.so, RTLD_LOCAL | RTLD_DEEPBIND)
`-> dlopen(libnodp.so, RTLD_LOCAL)
The following snippets are taken from LD_DEBUG to demonstrate the
RLTD_LOCAL and RTLD_DEEPBIND flags.
# dlopen("libdeep.so", RTLD_LOCAL | RTLD_DEEPBIND)
# scopes visible to libdeep.so, where scope [0] is the local one.
object=./libdeep.so [0]
scope 0: ./libdeep.so /usr/lib/libc.so.6 /lib64/ld-linux-x86-64.so.2
scope 1: ./main ./libprel.so ./liblink.so /usr/lib/libc.so.6 /lib64/ld-linux-x86-64.so.2
# main: dlsym(handle:libdeep.so, "test")
symbol=test; lookup in file=./libdeep.so [0]
binding file ./libdeep.so [0] to ./libdeep.so [0]: normal symbol `test'
# libdeep.so: dlsym(RTLD_NEXT, "next_libdeep")
symbol=next_libdeep; lookup in file=/usr/lib/libc.so.6 [0]
symbol=next_libdeep; lookup in file=/lib64/ld-linux-x86-64.so.2 [0]
./libdeep.so: error: symbol lookup error: undefined symbol: next_libdeep (fatal)
# libdeep.so: dlsym(RTLD_DEFAULT, "default_libdeep")
# first search local scope (DEEPBIND)
symbol=default_libdeep; lookup in file=./libdeep.so [0]
symbol=default_libdeep; lookup in file=/usr/lib/libc.so.6 [0]
symbol=default_libdeep; lookup in file=/lib64/ld-linux-x86-64.so.2 [0]
symbol=default_libdeep; lookup in file=./main [0]
symbol=default_libdeep; lookup in file=./libprel.so [0]
symbol=default_libdeep; lookup in file=./liblink.so [0]
symbol=default_libdeep; lookup in file=/usr/lib/libc.so.6 [0]
symbol=default_libdeep; lookup in file=/lib64/ld-linux-x86-64.so.2 [0]
./libdeep.so: error: symbol lookup error: undefined symbol: default_libdeep (fatal)
# main: dlsym(handle:libdeep.so, "libdeep_main")
symbol=libdeep_main; lookup in file=./libdeep.so [0]
symbol=libdeep_main; lookup in file=/usr/lib/libc.so.6 [0]
symbol=libdeep_main; lookup in file=/lib64/ld-linux-x86-64.so.2 [0]
./libdeep.so: error: symbol lookup error: undefined symbol: libdeep_main (fatal)
The following snippets are taken from LD_DEBUG to demonstrate the
RLTD_LOCAL flag without the RTLD_DEEPBIND flag.
# dlopen("libdeep.so", RTLD_LOCAL)
# scopes visible to libnodp.so, where scope [0] is the global one.
object=./libnodp.so [0]
scope 0: ./main ./libprel.so ./liblink.so /usr/lib/libc.so.6 /lib64/ld-linux-x86-64.so.2
scope 1: ./libnodp.so /usr/lib/libc.so.6 /lib64/ld-linux-x86-64.so.2
# main: dlsym(handle:libnodp.so, "test")
symbol=test; lookup in file=./libnodp.so [0]
binding file ./libnodp.so [0] to ./libnodp.so [0]: normal symbol `test'
# libnodp.so: dlsym(RTLD_NEXT, "next_libnodp")
symbol=next_libnodp; lookup in file=/usr/lib/libc.so.6 [0]
symbol=next_libnodp; lookup in file=/lib64/ld-linux-x86-64.so.2 [0]
./libnodp.so: error: symbol lookup error: undefined symbol: next_libnodp (fatal)
# libnodp.so: dlsym(RTLD_DEFAULT, "default_libnodp")
# first search global scope (no DEEPBIND)
symbol=default_libnodp; lookup in file=./main [0]
symbol=default_libnodp; lookup in file=./libprel.so [0]
symbol=default_libnodp; lookup in file=./liblink.so [0]
symbol=default_libnodp; lookup in file=/usr/lib/libc.so.6 [0]
symbol=default_libnodp; lookup in file=/lib64/ld-linux-x86-64.so.2 [0]
symbol=default_libnodp; lookup in file=./libnodp.so [0]
symbol=default_libnodp; lookup in file=/usr/lib/libc.so.6 [0]
symbol=default_libnodp; lookup in file=/lib64/ld-linux-x86-64.so.2 [0]
./libnodp.so: error: symbol lookup error: undefined symbol: default_libnodp (fatal)
# main: dlsym(handle:libnodp.so, "libnodp_main")
symbol=libnodp_main; lookup in file=./libnodp.so [0]
symbol=libnodp_main; lookup in file=/usr/lib/libc.so.6 [0]
symbol=libnodp_main; lookup in file=/lib64/ld-linux-x86-64.so.2 [0]
./libnodp.so: error: symbol lookup error: undefined symbol: libnodp_main (fatal)
The following is a global lookup from the main application, since
lib{deep,nodp}.so were loaded with RTLD_LOCAL, they are not visible in the
global symbol scope.
# main: dlsym(RTLD_DEFAULT, "default_main")
symbol=default_main; lookup in file=./main [0]
symbol=default_main; lookup in file=./libprel.so [0]
symbol=default_main; lookup in file=./liblink.so [0]
symbol=default_main; lookup in file=/usr/lib/libc.so.6 [0]
symbol=default_main; lookup in file=/lib64/ld-linux-x86-64.so.2 [0]
./main: error: symbol lookup error: undefined symbol: default_main (fatal)
Load lib with same name from different locations
The sources in ldso/samename show some experiments, loading the libs with the same name but potentially from different locations (paths).
Dynamic Linking (x86_64)
Dynamic linking basically works via one indirect jump. It uses a combination of
function trampolines (.plt section) and a function pointer table (.got.plt
section).
On the first call the trampoline sets up some metadata and then jumps to the
ld.so runtime resolve function, which in turn patches the table with the
correct function pointer.
.plt ....... procedure linkage table, contains function trampolines, usually
located in code segment (rx permission)
.got.plt ... global offset table for .plt, holds the function pointer table
Using radare2 we can analyze this in more detail:
[0x00401040]> pd 4 @ section..got.plt
;-- section..got.plt:
;-- .got.plt: ; [22] -rw- section size 32 named .got.plt
;-- _GLOBAL_OFFSET_TABLE_:
[0] 0x00404000 .qword 0x0000000000403e10 ; section..dynamic
[1] 0x00404008 .qword 0x0000000000000000
; CODE XREF from section..plt @ +0x6
[2] 0x00404010 .qword 0x0000000000000000
;-- reloc.puts:
; CODE XREF from sym.imp.puts @ 0x401030
[3] 0x00404018 .qword 0x0000000000401036 ; RELOC 64 puts
[0x00401040]> pd 6 @ section..plt
;-- section..plt:
;-- .plt: ; [12] -r-x section size 32 named .plt
┌─> 0x00401020 ff35e22f0000 push qword [0x00404008]
╎ 0x00401026 ff25e42f0000 jmp qword [0x00404010]
╎ 0x0040102c 0f1f4000 nop dword [rax]
┌ 6: int sym.imp.puts (const char *s);
└ ╎ 0x00401030 ff25e22f0000 jmp qword [reloc.puts]
╎ 0x00401036 6800000000 push 0
└─< 0x0040103b e9e0ffffff jmp sym..plt
- At address
0x00401030in the.pltsection we see the indirect jump forputsusing the function pointer in_GLOBAL_OFFSET_TABLE_[3] (GOT). GOT[3]initially points to instruction after theputstrampoline0x00401036.- This pushes the relocation index
0and then jumps to the first trampoline0x00401020. - The first trampoline jumps to
GOT[2]which will be filled at program startup by theld.sowith its resolve function. - The
ld.soresolve function fixes the relocation referenced by the relocation index pushed by theputstrampoline. - The relocation entry at index
0tells the resolve function which symbol to search for and where to put the function pointer:
As we can see the offset from relocation at index> readelf -r <main> >> Relocation section '.rela.plt' at offset 0x4b8 contains 1 entry: >> Offset Info Type Sym. Value Sym. Name + Addend >> 000000404018 000200000007 R_X86_64_JUMP_SLO 0000000000000000 puts@GLIBC_2.2.5 + 00points toGOT[3].
ELF Symbol Versioning
The ELF symbol versioning mechanism allows to attach version information to symbols. This can be used to express symbol version requirements or to provide certain symbols multiple times in the same ELF file with different versions (eg for backwards compatibility).
The libpthread.so library is an example which provides the
pthread_cond_wait symbol multiple times but in different versions.
With readelf the version of the symbol can be seen after the @.
> readelf -W --dyn-syms /lib/libpthread.so
Symbol table '.dynsym' contains 342 entries:
Num: Value Size Type Bind Vis Ndx Name
...
141: 0000f080 696 FUNC GLOBAL DEFAULT 16 pthread_cond_wait@@GLIBC_2.3.2
142: 00010000 111 FUNC GLOBAL DEFAULT 16 pthread_cond_wait@GLIBC_2.2.5
The @@ denotes the default symbol version which will be used during
static linking against the library.
The following dump shows that the tmp program linked against lpthread will
depend on the symbol version GLIBC_2.3.2, which is the default version.
> echo "#include <pthread.h>
int main() {
return pthread_cond_wait(0,0);
}" | gcc -o tmp -xc - -lpthread;
readelf -W --dyn-syms tmp | grep pthread_cond_wait;
Symbol table '.dynsym' contains 7 entries:
Num: Value Size Type Bind Vis Ndx Name
...
2: 00000000 0 FUNC GLOBAL DEFAULT UND pthread_cond_wait@GLIBC_2.3.2 (2)
Only one symbol can be annotated as the
@@default version.
Using the --version-info flag with readelf, more details on the symbol
version info compiled into the tmp ELF file can be obtained.
- The
.gnu.versionsection contains the version definition for each symbol in the.dynsymsection.pthread_cond_waitis at index2in the.dynsymsection, the corresponding symbol version is at index2in the.gnu.versionsection. - The
.gnu.version_rsection contains symbol version requirements per shared library dependency (DT_NEEDEDdynamic entry).
> readelf -W --version-info --dyn-syms tmp
Symbol table '.dynsym' contains 7 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 NOTYPE WEAK DEFAULT UND _ITM_deregisterTMCloneTable
2: 0000000000000000 0 FUNC GLOBAL DEFAULT UND pthread_cond_wait@GLIBC_2.3.2 (2)
3: 0000000000000000 0 FUNC GLOBAL DEFAULT UND __libc_start_main@GLIBC_2.2.5 (3)
4: 0000000000000000 0 NOTYPE WEAK DEFAULT UND __gmon_start__
5: 0000000000000000 0 NOTYPE WEAK DEFAULT UND _ITM_registerTMCloneTable
6: 0000000000000000 0 FUNC WEAK DEFAULT UND __cxa_finalize@GLIBC_2.2.5 (3)
Version symbols section '.gnu.version' contains 7 entries:
Addr: 0x0000000000000534 Offset: 0x000534 Link: 6 (.dynsym)
000: 0 (*local*) 0 (*local*) 2 (GLIBC_2.3.2) 3 (GLIBC_2.2.5)
004: 0 (*local*) 0 (*local*) 3 (GLIBC_2.2.5)
Version needs section '.gnu.version_r' contains 2 entries:
Addr: 0x0000000000000548 Offset: 0x000548 Link: 7 (.dynstr)
000000: Version: 1 File: libc.so.6 Cnt: 1
0x0010: Name: GLIBC_2.2.5 Flags: none Version: 3
0x0020: Version: 1 File: libpthread.so.0 Cnt: 1
0x0030: Name: GLIBC_2.3.2 Flags: none Version: 2
The gnu dynamic linker allows to inspect the version processing during runtime
by setting the LD_DEBUG environment variable accordingly.
# version: Display version dependencies.
> LD_DEBUG=versions ./tmp
717904: checking for version `GLIBC_2.2.5' in file /usr/lib/libc.so.6 [0] required by file ./tmp [0]
717904: checking for version `GLIBC_2.3.2' in file /usr/lib/libpthread.so.0 [0] required by file ./tmp [0]
...
# symbols : Display symbol table processing.
# bindings: Display information about symbol binding.
> LD_DEBUG=symbols,bindings ./tmp
...
718123: symbol=pthread_cond_wait; lookup in file=./tmp [0]
718123: symbol=pthread_cond_wait; lookup in file=/usr/lib/libpthread.so.0 [0]
718123: binding file ./tmp [0] to /usr/lib/libpthread.so.0 [0]: normal symbol `pthread_cond_wait' [GLIBC_2.3.2]
Example: version script
The following shows an example C++ library libfoo which provides the same
symbol multiple times but in different versions.
// file: libfoo.cc
#include<stdio.h>
// Bind function symbols to version nodes.
//
// ..@ -> Is the unversioned symbol.
// ..@@.. -> Is the default symbol.
__asm__(".symver func_v0,func@");
__asm__(".symver func_v1,func@LIB_V1");
__asm__(".symver func_v2,func@@LIB_V2");
extern "C" {
void func_v0() { puts("func_v0"); }
void func_v1() { puts("func_v1"); }
void func_v2() { puts("func_v2"); }
}
__asm__(".symver _Z11func_cpp_v1i,_Z8func_cppi@LIB_V1");
__asm__(".symver _Z11func_cpp_v2i,_Z8func_cppi@@LIB_V2");
void func_cpp_v1(int) { puts("func_cpp_v1"); }
void func_cpp_v2(int) { puts("func_cpp_v2"); }
void func_cpp(int) { puts("func_cpp_v2"); }
Version script for libfoo which defines which symbols for which versions are
exported from the ELF file.
# file: libfoo.ver
LIB_V1 {
global:
func;
extern "C++" {
"func_cpp(int)";
};
local:
*;
};
LIB_V2 {
global:
func;
extern "C++" {
"func_cpp(int)";
};
} LIB_V1;
The local: section in
LIB_V1is a catch all, that matches any symbol not explicitly specified, and defines that the symbol is local and therefore not exported from the ELF file.
The library libfoo can be linked with the version definitions in libfoo.ver
by passing the version script to the linker with the --version-script flag.
> g++ -shared -fPIC -o libfoo.so libfoo.cc -Wl,--version-script=libfoo.ver
> readelf -W --dyn-syms libfoo.so | c++filt
Symbol table '.dynsym' contains 14 entries:
Num: Value Size Type Bind Vis Ndx Name
...
6: 0000000000000000 0 OBJECT GLOBAL DEFAULT ABS LIB_V1
7: 000000000000114b 29 FUNC GLOBAL DEFAULT 13 func_cpp(int)@LIB_V1
8: 0000000000001168 29 FUNC GLOBAL DEFAULT 13 func_cpp(int)@@LIB_V2
9: 0000000000001185 29 FUNC GLOBAL DEFAULT 13 func_cpp(int)@@LIB_V1
10: 0000000000000000 0 OBJECT GLOBAL DEFAULT ABS LIB_V2
11: 0000000000001109 22 FUNC GLOBAL DEFAULT 13 func
12: 000000000000111f 22 FUNC GLOBAL DEFAULT 13 func@LIB_V1
13: 0000000000001135 22 FUNC GLOBAL DEFAULT 13 func@@LIB_V2
The following program demonstrates how to make use of the different versions:
// file: main.cc
#include <dlfcn.h>
#include <assert.h>
// Links against default symbol in the lib.so.
extern "C" void func();
int main() {
// Call the default version.
func();
#ifdef _GNU_SOURCE
typedef void (*fnptr)();
// Unversioned lookup.
fnptr fn_v0 = (fnptr)dlsym(RTLD_DEFAULT, "func");
// Version lookup.
fnptr fn_v1 = (fnptr)dlvsym(RTLD_DEFAULT, "func", "LIB_V1");
fnptr fn_v2 = (fnptr)dlvsym(RTLD_DEFAULT, "func", "LIB_V2");
assert(fn_v0 != 0);
assert(fn_v1 != 0);
assert(fn_v2 != 0);
fn_v0();
fn_v1();
fn_v2();
#endif
return 0;
}
Compiling and running results in:
> g++ -o main main.cc -ldl ./libfoo.so && ./main
func_v2
func_v0
func_v1
func_v2
References
- ELF Symbol Versioning
- Binutils ld: Symbol Versioning
- LSB: Symbol Versioning
- How To Write Shared Libraries
- LSB: ELF File Format
python
Decorator [run]
Some decorator examples with type annotation.
from typing import Callable
def log(f: Callable[[int], None]) -> Callable[[int], None]:
def inner(x: int):
print(f"log::inner f={f.__name__} x={x}")
f(x)
return inner
@log
def some_fn(x: int):
print(f"some_fn x={x}")
def log_tag(tag: str) -> Callable[[Callable[[int], None]], Callable[[int], None]]:
def decorator(f: Callable[[int], None]) -> Callable[[int], None]:
def inner(x: int):
print(f"log_tag::inner f={f.__name__} tag={tag} x={x}")
f(x)
return inner
return decorator
@log_tag("some_tag")
def some_fn2(x: int):
print(f"some_fn2 x={x}")
Walrus operator [run]
Walrus operator := added since python 3.8.
from typing import Optional
# Example 1: if let statements
def foo(ret: Optional[int]) -> Optional[int]:
return ret
if r := foo(None):
print(f"foo(None) -> {r}")
if r := foo(1337):
print(f"foo(1337) -> {r}")
# Example 2: while let statements
toks = iter(['a', 'b', 'c'])
while tok := next(toks, None):
print(f"{tok}")
# Example 3: list comprehension
print([tok for t in [" a", " ", " b "] if (tok := t.strip())])
Unittest [run]
Run unittests directly from the command line as
python3 -m unittest -v test
Optionally pass -k <patter> to only run subset of tests.
# file: test.py
import unittest
class MyTest(unittest.TestCase):
def setUp(self):
pass
def tearDown(self):
pass
# Tests need to start with the prefix 'test'.
def test_foo(self):
self.assertEqual(1 + 2, 3)
def test_bar(self):
with self.assertRaises(IndexError):
list()[0]
Doctest [run]
Run doctests directly from the command line as
python -m doctest -v test.py
# file: test.py
def sum(a: int, b: int) -> int:
"""Sum a and b.
>>> sum(1, 2)
3
>>> sum(10, 20)
30
"""
return a + b
timeit
Micro benchmarking.
python -m timeit '[x.strip() for x in ["a ", " b"]]'
gcov(1)
Generate code coverage reports in text format.
Compile the source files of interest and link the final binary with the following flags:
-fprofile-arcsinstruments the generated code such that it writes a.gcdafile when being executed with details about which branches are taken-ftest-coveragewrites a.gcnonotes file which is used bygcovduring generation of the coverage report
Depending on the build environment one may also set -fprofile-abs-path to
generate absolute path names into the .gcno note files, this can ease setups
where compilations are done in different directories to the source directory.
gcc/clangalso support an alias flag--coveragewhich during compilation time is equivalent to-fprofile-arcs -ftest-coverageand during link time-lgcov.
After running the instrumented binary, the human readable report can then be generated for a single file for example such as
gcov <SRC FILE | OBJ FILE>
Example
#include <cstdio>
void tell_me(int desc) {
if (desc & 1) {
std::puts("this");
} else {
std::puts("that");
}
}
int main(int argc, char *argv[]) {
tell_me(argc);
tell_me(argc);
return 0;
}
The gcov coverage report can be generated as follows for gcc or clang.
CXXFLAGS = -fprofile-arcs -ftest-coverage
# or the alias
#CXXFLAGS = --coverage
cov-gcc: clean
g++ $(CXXFLAGS) -c -o cov.o cov.cc
g++ $(CXXFLAGS) -o $@ cov.o
./$@
gcov --demangled-names cov.cc
cat cov.cc.gcov
.PHONY: cov-gcc
cov-clang: clean
clang++ $(CXXFLAGS) -c -o cov.o cov.cc
clang++ $(CXXFLAGS) -o $@ cov.o
./$@
llvm-cov gcov --demangled-names cov.cc
cat cov.cc.gcov
.PHONY: cov-clang
clean:
$(RM) *.gcov *.gcno *.gcda *.o cov-*
The will generate a report similar to the following.
cat cov.cc.gcov
-: 0:Source:cov.cc
-: 0:Graph:cov.gcno
-: 0:Data:cov.gcda
-: 0:Runs:1
-: 1:// Copyright (C) 2023 johannst
-: 2:
-: 3:#include <cstdio>
-: 4:
2: 5:void tell_me(int desc) {
2: 6: if (desc & 1) {
2: 7: std::puts("this");
-: 8: } else {
#####: 9: std::puts("that");
-: 10: }
2: 11:}
-: 12:
1: 13:int main(int argc, char *argv[]) {
1: 14: tell_me(argc);
1: 15: tell_me(argc);
1: 16: return 0;
-: 17:}
Profile guided optimization (pgo)
pgo is an optimization technique to optimize a program for its usual
workload.
It is applied in two phases:
- Collect profiling data (best with representative benchmarks).
- Optimize program based on collected profiling data.
The following simple program is used as demonstrator.
#include <stdio.h>
#define NOINLINE __attribute__((noinline))
NOINLINE void foo() { puts("foo()"); }
NOINLINE void bar() { puts("bar()"); }
int main(int argc, char *argv[]) {
if (argc == 2) {
foo();
} else {
bar();
}
}
clang
On the actual machine with clang 15.0.7, the following code is generated for
the main() function.
# clang -o test test.c -O3
0000000000001160 <main>:
1160: 50 push rax
; Jump if argc != 2.
1161: 83 ff 02 cmp edi,0x2
1164: 75 09 jne 116f <main+0xf>
; foor() is on the hot path (fall-through).
1166: e8 d5 ff ff ff call 1140 <_Z3foov>
116b: 31 c0 xor eax,eax
116d: 59 pop rcx
116e: c3 ret
; bar() is on the cold path (branch).
116f: e8 dc ff ff ff call 1150 <_Z3barv>
1174: 31 c0 xor eax,eax
1176: 59 pop rcx
1177: c3 ret
The following shows how to compile with profiling instrumentation and how to optimize the final program with the collected profiling data (llvm pgo).
The arguments to ./test are chosen such that 9/10 runs call bar(), which
is currently on the cold path.
# Compile test program with profiling instrumentation.
clang -o test test.cc -O3 -fprofile-instr-generate
# Collect profiling data from multiple runs.
for i in {0..10}; do
LLVM_PROFILE_FILE="prof.clang/%p.profraw" ./test $(seq 0 $i)
done
# Merge raw profiling data into single profile data.
llvm-profdata merge -o pgo.profdata prof.clang/*.profraw
# Optimize test program with profiling data.
clang -o test test.cc -O3 -fprofile-use=pgo.profdata
NOTE: If
LLVM_PROFILE_FILEis not given the profile data is written todefault.profrawwhich is re-written on each run. If theLLVM_PROFILE_FILEcontains a%min the filename, a unique integer will be generated and consecutive runs will update the same generated profraw file,LLVM_PROFILE_FILEcan specify a new file every time, however that requires more storage in general.
After optimizing the program with the profiling data, the main() function
looks as follows.
0000000000001060 <main>:
1060: 50 push rax
; Jump if argc == 2.
1061: 83 ff 02 cmp edi,0x2
1064: 74 09 je 106f <main+0xf>
; bar() is on the hot path (fall-through).
1066: e8 e5 ff ff ff call 1050 <_Z3barv>
106b: 31 c0 xor eax,eax
106d: 59 pop rcx
106e: c3 ret
; foo() is on the cold path (branch).
106f: e8 cc ff ff ff call 1040 <_Z3foov>
1074: 31 c0 xor eax,eax
1076: 59 pop rcx
1077: c3 ret
gcc
With gcc 13.2.1 on the current machine, the optimizer puts bar() on the
hot path by default.
0000000000001040 <main>:
1040: 48 83 ec 08 sub rsp,0x8
; Jump if argc == 2.
1044: 83 ff 02 cmp edi,0x2
1047: 74 0c je 1055 <main+0x15>
; bar () is on the hot path (fall-through).
1049: e8 22 01 00 00 call 1170 <_Z3barv>
104e: 31 c0 xor eax,eax
1050: 48 83 c4 08 add rsp,0x8
1054: c3 ret
; foo() is on the cold path (branch).
1055: e8 06 01 00 00 call 1160 <_Z3foov>
105a: eb f2 jmp 104e <main+0xe>
105c: 0f 1f 40 00 nop DWORD PTR [rax+0x0]
The following shows how to compile with profiling instrumentation and how to optimize the final program with the collected profiling data.
The arguments to ./test are chosen such that 2/3 runs call foo(), which
is currently on the cold path.
gcc -o test test.cc -O3 -fprofile-generate
./test 1
./test 1
./test 2 2
gcc -o test test.cc -O3 -fprofile-use
NOTE: Consecutive runs update the generated
test.gcdaprofile data file rather than re-write it.
After optimizing the program with the profiling data, the main() function
0000000000001040 <main.cold>:
; bar() is on the cold path (branch).
1040: e8 05 00 00 00 call 104a <_Z3barv>
1045: e9 25 00 00 00 jmp 106f <main+0xf>
0000000000001060 <main>:
1060: 51 push rcx
; Jump if argc != 2.
1061: 83 ff 02 cmp edi,0x2
1064: 0f 85 d6 ff ff ff jne 1040 <main.cold>
; for() is on the hot path (fall-through).
106a: e8 11 01 00 00 call 1180 <_Z3foov>
106f: 31 c0 xor eax,eax
1071: 5a pop rdx
1072: c3 ret
Linux
systemd
systemctl
Inspect units:
systemctl [opts] [cmd]
[opts]
--user
--type=TYPE List only given types eg, service, timer, socket (use --type=help for a list)
--state=STATE List only given states eg running, enabled (use --state=help for a list)
--failed List only failed services
[cmd]
list-units <pattern> List units in memory
status <unit> Show runtime status of unit
start <unit> Start a unit
stop <unit> Stop a unit
restart <unit> Restart a unit
reload <unit> Reload a unit
enable <unit> Enable a unit (persistent)
disable <unit> Disable a unit
cat <unit> Print unit file
show <unit> Show properties of unit
Example: List failed units
# List all system failed units.
systemctl --failed
# List all user failed units.
systemctl --user --failed
Example: Trivial user unit
# Generate unit
mkdir -p ~/.config/systemd/user
echo '[Unit]
Description=Test logger
[Service]
Type=oneshot
ExecStart=logger "Hello from test unit"' > ~/.config/systemd/user/test.service
# Run unit
systemctl --user start test
# See log message
journalctl --user -u test -n 5
journalctl
Inspect journal logs:
journalctl [opts] [matches]
--user Current user journal (system by default)
-u <unit> Show logs for specified <unit>
-n <lines> Show only last <lines>
-f Follow journal
-g <pattern> Grep for <pattern>
Cleanup:
journalctl [opts]
--disk-usage Show current disk usage
--vacuum-size=<size> Reduce journal log to <size> (K/M/G)
References
core(5)
There are multiple requirements that must be satisfied that coredumps are
being generated, a full list can be found in core(5).
An important one is to configure the soft resource limit RLMIT_CORE
(typically as unlimited during debugging).
In a typical bash/zsh this can be done as
ulimit -Sc unlimited
Naming of coredump files
There are two important kernel configs to control the naming:
/proc/sys/kernel/core_pattern
<pattern> => Specifies a name pattern for the coredump file. This can
include certain FORMAT specifier.
|<cmdline> => Coredump is pipe through stdin to the user space process
specified by the cmdline, this can also contain FORMAT specifier.
FORMAT specifier (full list, see core(5)):
%E Pathname of the executable ('/' replaced by '!').
%p PID of the dumping process in its pid namespace.
%P PID of the dumping process in the initial pid namespace.
%u Real UID of dumping process.
%s Signal number causing the dump.
/proc/sys/kernel/core_uses_pid
1 => Append ".<pid>" suffic to the coredump file name
(pid of the dumping process).
0 => Do not append the suffix.
Control which segments are dumped
Each process has a coredump filter defined in /proc/<pid>/coredump_filter
which specifies which memory segments are being dumped.
Filters are preseved across fork/exec calls and hence child processes inherit
the parents filters.
The filter is a bitmask where 1 indicates to dump the given type.
From core(5):
bit 0 Dump anonymous private mappings.
bit 1 Dump anonymous shared mappings.
bit 2 Dump file-backed private mappings.
bit 3 Dump file-backed shared mappings.
bit 4 Dump ELF headers.
bit 5 Dump private huge pages.
bit 6 Dump shared huge pages.
bit 7 Dump private DAX pages.
bit 8 Dump shared DAX pages.
Default filter 0x33.
Some examples out there
coredumpctl (systemd)
# List available coredumps.
coredumpctl list
TIME PID UID GID SIG COREFILE EXE SIZE
...
Fri 2022-03-11 12:10:48 CET 6363 1000 1000 SIGSEGV present /usr/bin/sleep 18.1K
# Get detailed info on specific coredump.
coredumpctl info 6363
# Debug specific coredump.
coredumpctl debug 6363
# Dump specific coredump to file.
coredumpctl dump 6363 -o <file>
apport (ubuntu)
Known crash report locations:
/var/crash
To get to the raw coredump, crash reports can be unpacked as:
apport-unpack <crash_repot> <dest_dir>
The coredump resides under <dest_dir>/CoreDump.
ptrace_scope
In case the kernel was compiled with the yama security module
(CONFIG_SECURITY_YAMA), tracing processes with ptrace(2) can be restricted.
/proc/sys/kernel/yama/ptrace_scope
0 => No restrictions.
1 => Restricted attach, only the following can attach
- A process in the parent hierarchy.
- A process with CAP_SYS_PTRACE.
- A process with the PID that the tracee allowed by via
PR_SET_PTRACER.
2 => Only processes with CAP_SYS_PTRACE in the user namespace of the tracee
can attach.
3 => No tracing allowed.
Further details in ptrace(2).
cryptsetup(8)
cryptsetup <action> [opts] <action args>
action:
open <dev> <name> --type <type> Open (decrypt) <dev> and map with <name>.
Mapped as /dev/mapper/<name>.
Type: {luks,plain,tcrypt,bitlk}
close <name> Close existing mapping <name>.
status <name> Print status for mapping <name>.
luksFormat <dev> Create new LUKS partition and set initial passphrase.
(Keyslot 0)
luksAddKey <dev> Add a new passphrase.
luksRemoveKey <dev> Remove existing passphrase.
luksChangeKey <dev> Change existing passphrase.
lusDump <dev> Dump LUKS header for device.
Example: Create LUKS encrypted disk.
For this example we use a file as backing storage and set it up as loop(4) device. The loop device can be replaced by any block device file.
Optional: Overwrite existing data on disk.
sudo dd if=/dev/urandom of=/dev/sdX bs=1M
First create the backing file and setup the loop device.
# Create 100MB file.
dd if=/dev/zero of=blkfile bs=1M count=100
# Attach file to first free (-f) loop device
sudo losetup -f ./blkfile
# List loop devices.
sudo losetup -l
# NAME SIZELIMIT OFFSET AUTOCLEAR RO BACK-FILE DIO LOG-SEC
# /dev/loop0 0 0 0 0 /home/johannst/blkfile 0 512
Create a new LUKS partition and format new filesystem.
# Initialize LUKS partition and set initial passphrase.
sudo cryptsetup luksFormat /dev/loop0
file blkfile
# blkfile: LUKS encrypted file, ver 2 [, , sha256] UUID: 8...
# Open (decrypt) the LUKS device, it will be mapped under /dev/mapper/loop0.
sudo cryptsetup open --type luks /dev/loop0 loop0
# Format partition with new filesystem.
sudo mkfs.vfat /dev/mapper/loop0
lsblk -f
# NAME FSTYPE FSVER LABEL UUID FSAVAIL FSUSE% MOUNTPOINTS
# loop0 crypto_LU 2 8...
# └─loop0 vfat FAT16 D... 83.8M 0% /home/johannst/mnt
# Close (re-encrypt) LUKS device.
sudo cryptsetup close loop0
Example: Using an existing LUKS device.
# Open (decrypt) the LUKS device, it will be mapped under /dev/mapper/loop0.
sudo cryptsetup open --type luks /dev/loop0 loop0
# Mount filesystem.
sudo mount /dev/mapper/loop0 <mntpoint>
# Use disk ...
# Unmount filesystem.
sudo umount <mntpoint>
# Close (re-encrypt) LUKS device.
sudo cryptsetup close loop0
swap
List active swap areas
# procfs
cat /proc/swaps
# cli tool
swapon --show
Manual swapfile setup
# One time:
# Create and initialize swapfile.
# mkswap will initialize swap area over full filesize by default.
sudo dd if=/dev/zero of=/swapfile bs=1G count=1
mkswap /swapfile
# Enable swap file (until next reboot).
swapon /swapfile
# Persistent setup of swap file.
echo "/swapfile none swap sw 0 0" | sudo tee -a /etc/fstab
# Disable swap file (until next reboot).
swapoff /swapfile
Recommended file permissions
0600and file owneruid=0 (root).
Using dphys-swapfile service.
Dynamically computes size of swap file based on installed RAM.
# Setup and enable swap based on /etc/dphys-swapfile.
dphys-swapfile setup
dphys-swapfile swapon
# Disable swap on configured file.
dphys-swapfile swapoff
Usually comes with a script to be automatically run at system startup and shutdown. For example as
systemdservice:systemctl status dphys-swapfile
Linux input
Some notes on using /dev/input/* device driver files.
mouseX / mice
These device files are created by the mousedev driver.
/dev/input/mouseXrepresents the input stream for a SINGLE mouse device./dev/input/micerepresents the merged input stream for ALL mouse devices.
The data stream consists of 3 bytes per event. An event is encoded as (BTN, X, Y).
BTNbutton pressedXmovement in x-direction-1 -> leftand1 -> rightYmovement in y-direction-1 -> downand1 -> up
The raw data stream can be inspected as follows.
sudo cat /dev/input/mice | od -tx1 -w3 -v
eventX
These device files are created by the evdev driver.
/dev/input/eventXrepresents the generic input event interface a SINGLE input device.
Input events are encoded as given by the input_event struct below. Reading
from the eventX device file will always yield whole number of input events.
struct input_event {
struct timeval time;
unsigned short type;
unsigned short code;
unsigned int value;
};
On most 64bit machines the raw data stream can be inspected as follows.
sudo cat /dev/input/event4 | od -tx1 -w24 -v
Identifying device files.
To find out which device file is assigned to which input device the following
file /proc/bus/input/devices in the proc filesystem can be consulted.
This yields entries as follows and shows which Handlers are assigned to which
Name.
I: Bus=0018 Vendor=04f3 Product=0033 Version=0000
N: Name="Elan Touchpad"
...
H: Handlers=event15 mouse0
...
Example: Toying with /dev/input/eventX
Once compiled, the example should be run as sudo ./event /dev/input/eventX.
#include <stdio.h>
#include <fcntl.h>
#include <assert.h>
#include <unistd.h>
#include <time.h>
#include <sys/time.h>
#include <linux/input-event-codes.h>
struct input_event {
struct timeval time;
unsigned short type;
unsigned short code;
unsigned int value;
};
const char* type(unsigned short t) {
static char buf[32];
const char* fmt = "0x%x";
switch (t) {
#define FMT(TYPE) case TYPE: fmt = #TYPE"(0x%x)"; break
FMT(EV_SYN);
FMT(EV_KEY);
FMT(EV_REL);
FMT(EV_ABS);
#undef FMT
}
snprintf(buf, sizeof(buf), fmt, t);
return buf;
}
const char* code(unsigned short c) {
static char buf[32];
const char* fmt = "0x%x";
switch (c) {
#define FMT(CODE) case CODE: fmt = #CODE"(0x%x)"; break
FMT(BTN_LEFT);
FMT(BTN_RIGHT);
FMT(BTN_MIDDLE);
FMT(REL_X);
FMT(REL_Y);
#undef FMT
}
snprintf(buf, sizeof(buf), fmt, c);
return buf;
}
const char* timefmt(const struct timeval* t) {
assert(t);
struct tm* lt = localtime(&t->tv_sec); // Returns pointer to static tm object.
static char buf[64];
strftime(buf, sizeof(buf), "%H:%M:%S", lt);
return buf;
}
int main(int argc, char* argv[]) {
assert(argc == 2);
int fd = open(argv[1], O_RDONLY);
assert(fd != -1);
struct input_event inp;
while (1) {
int ret = read(fd, &inp, sizeof(inp));
assert(ret == sizeof(inp));
printf("time: %s type: %s code: %s value: 0x%x\n",
timefmt(&inp.time), type(inp.type), code(inp.code), inp.value);
}
}
access control list (acl)
This describes
POSIXacl.
The access control list provides a flexibel permission mechanism next to the
UNIX file permissions. This allows to specify fine grained permissions for
users/groups on filesystems.
Filesystems which support acl typically have an acl option, which must be
specified while mounting when it is not a default option.
Filesystems must be mounted with the acl option if not enabled as default
option.
Files or folder that have an acl defined, can be identified by the + sign
next to the UNIX permissions.
The following shows on example for a zfs filesystem.
# mount | grep tank
tank on /tank type zfs (rw,xattr,noacl)
tank/foo on /tank/foo type zfs (rw,xattr,posixacl)
# ls -h /tank
drwxrwxr-x+ 2 root root 4 11. Jun 14:26 foo/
Show acl entries
# List current acl entries.
getfacl /tank/foo
Modify acl entries
# Add acl entry for user "user123".
setfacl -m "u:user123:rwx" /tank/foo
# Remove entry for user "user123".
setfacl -x "u:user123" /tank/foo
# Add acl entry for group "group456".
setfacl -m "g:group456:rx" /tank/foo
# Add acl entry for others.
setfacl -m "o:rx" /tank/foo
# Remove extended acl entries.
setfacl -b /tank/foo
Masking of acl entries
The mask defines the maximum access rights that can be given to users and
groups.
# Update the mask.
setfacl -m "m:rx" /tank/foo
# List acl entries.
getfacl /tank/foo
# file: tank/foo
# owner: root
# group: root
user::rwx
user:user123:rwx # effective:r-x
group::r-x
mask::r-x
other::rwx
References
zfs
Pools are managed with the zpool(8) command and have the
following hierarchy:
pool: consists of one or more virtual devices (vdev)vdev: consists of one or more physical devices (dev) and come in different kinds such asdisk,mirror,raidzX, ...disk: single physical disk (vdev == dev)mirror: data is identically replicated on alldevs(requires at least 2 physical devices).
Data stored in a pool is distributed and stored across all vdevs by zfs.
Therefore a total failure of a single vdev can lead to total loss of a pool.
A dataset is a logical volume which can be created on top of a pool. Each
dataset can be configured with its own set of properties like
encryption, quota, ....
Datasets are managed with the zfs(8) command.
zfs pool management
Pools are by default mounted at /<POOL>.
Create, modify and destroy zfs pools
# Create a pool MOOSE with a two mirror vdevs.
zpool create moose mirror <dev1> <dev2> mirror <dev3> <dev4>..
# Add new raidz1 vdev to a pool.
zpool add moose raidz1 <devA> <devB> <devC>..
# Remove a vdev from a pool.
zpool remove moose <vdevX>
# Destroy a pool.
zpool destroy moose
For stable device names in small home setups it is recommended to use names from
/dev/disk/by-id.
Inspect zfs pools
# Show status of all pools or a single one.
zpool status [<pool>]
# Show information / statistics about pools or single one.
zpool list [<pool>]
# Show statistics for all devices.
zpool list -v
# Show command history for pools.
zpool history
Modify vdevs
# vdev MIRROR-0 with two devs.
zpool status
NAME STATE READ WRITE CKSUM
moose ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
virtio-200 ONLINE 0 0 0
virtio-300 ONLINE 0 0 0
# Attach new device to an existing vdev.
zpool attach moose virtio-200 virtio-400
# vdev MIRROR-0 with three devs.
zpool status
NAME STATE READ WRITE CKSUM
moose ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
virtio-200 ONLINE 0 0 0
virtio-300 ONLINE 0 0 0
virtio-400 ONLINE 0 0 0
# Detach device from vdev.
zpool detach moose virtio-200
Replace faulty disk
# MIRROR-0 is degraded as one disk failed, but still intact.
zpool status
NAME STATE READ WRITE CKSUM
moose DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
virtio-200 UNAVAIL 0 0 0 invalid label
virtio-300 ONLINE 0 0 0
# Replace faulty disk, in mirror.
# No data is lost since mirror still has one good disk.
zpool replace moose virtio-200 virtio-400
# MIRROR-0 back in ONLINE (good) state.
zpool status
NAME STATE READ WRITE CKSUM
moose ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
virtio-400 ONLINE 0 0 0
virtio-300 ONLINE 0 0 0
Import or export zfs pools
When moving pools between hosts, the pool must be exported on the currently
active host and imported on the new host.
# Export a pool called MOOSE.
zpool export moose
# If datasets are busy, use lsof to check which processes keep it busy.
# lsof <mntpoint>
# List pools that can be imported using BY-ID deivce names (for example).
zpool import -d /dev/disk/by-id
# Import pool MOOSE using BY-ID device names (for example).
zpool import -d /dev/disk/by-id moose
Device names used by an existing pool can be changed by exporting and importing a pool again.
zfs dataset management
Datasets are by default mounted at /<POOL>/<DATASET>.
Create and destroy zfs datasets
# Create dataset FOO on pool MOOSE.
zfs create moose/foo
# Destroy dataset.
zfs destroy moose/foo
List all zfs datasets
# List all zfs datasets.
zfs list
Mount zfs datasets
# List currently mounted datasets.
zfs mount
# Mount dataset.
zfs mount moose/foo
# Unmount dataset.
zfs unmount moose/foo
Encrypted datasets
Encryption is a readonly property, can only be set when creating a dataset.
# Create encrypted dataset FOO on pool MOOSE.
zfs create -o encryption=on -o keyformat=passphrase moose/foo
# Mount encrypte dataset and load encryption key (if not loaded).
zfs mount -l moose/foo
# -l is equivalent to first loading the key via zfs load-key moose/foo.
# Unmount dataset and unload encryption key (unload is optional).
zfs umount -u moose/foo
Manage zfs encryption keys
# Preload encryption key for dataset.
zfs load-key moose/foo
# Preload encryption key for all datasets.
zfs load-key -a
# Change encryption key for dataset.
zfs change-key moose/foo
# Unload encryption key for dataset.
zfs unload-key moose/foo
Manage dataset properties
# Get all properties for dataset.
zfs get quota moose/foo
# Get single property for dataset.
zfs get all moose/foo
# Get single property for all datasets.
zfs get quota
# Set property on dataset.
zfs set quota=10G moose/foo
Snapshots
# Create snapshot called V2 for dataset moose/foo.
zfs snapshot moose/foo@v2
# List all snapshots.
zfs list -t snapshot
# Make .zfs direcotry visible in the root of the dataset.
zfs set snapdir=visible moose/foo
# Browse available snapshots in visible .zfs direcotry (readonly).
ls /moose/foo/.zfs/snapshot
v1/ v2/
# Create a new dataset based on the V1 snapshot
zfs clone moose/foo@v1 moose/foov1
# Destroy snapshot.
zfs destroy moose/foo@v1
Access control list
Focus on posix acl.
# Set the ACL type for the FOO dataset to POSIXACL.
zfs set acltype=posixacl moose/foo
# Get the ACL type of a given dataset.
zfs get acltype moose/foo
For performance reasons it is recommended to also set
zfs set xattr=sa moose/foo[ref].
Example: zfs pool import during startup (systemd)
The default zpool cache file is /etc/zfs/zpool.cache. When pools are imported
the cache is updated.
Enable the following targets / services to automatically import pools from the cache.
systemctl list-dependencies
...
└─zfs.target
└─zfs-import.target
└─zfs-import-cache.service
cpufreq
The sysfs interface to cpu frequency settings and current state.
/sys/devices/system/cpu/cpu*/cpufreq/
cpupower(1)
A CLI interface to peek and poke the cpu frequency settings.
# Show current frequency of all cores.
cpupower -c all frequency-info -f -m
# Show currently set frequency governor.
cpupower -c all frequency-info -p
# List available frequency governors.
cpupower -c all frequency-info -g
# Change frequency governor to POWERSAVE (eg).
cpupower -c all frequency-set -g powersave
Example
Watch cpu frequency.
watch -n1 "cpupower -c all frequency-info -f -m | xargs -n2 -d'\n'"
cups(1)
Discover
# List available printer driver.
lpinfo -m
# List available printer devices (connected + network).
lpinfo -v
Install printer
# Add device with PRINTER name, practically all modern network printer use the
# everywhere driver.
lpadmin -p PRINTER -m everywhere -v DEVICE_URI
# Delete named printer.
lpadmin -x PRINTER
Printer & Printing options
# List printer options.
# CHECK printer-make-and-model
lpoptions -p PRINTER
# List printing options.
lpoptions -p PRINTER -l
# Set an options, eg duplex mode.
lpoptions -p PRINTER -o 'Duplex=DuplexNoTumble
# Set the default printer (stored in ~/.cups/lpoptions).
lpoptions -d PRINTER
Inspect installed printer.
# List default printer.
lpstat -d
# List installed printer (-l for longer output).
lpstat -p
# List printer accepting state.
lpstat -a
# List printer and the attached device (eg device uri).
lpstat -v
# List all states at once.
lpstat -t
Print jobs
# Create print job.
lp -d PRINTER FILE
-n NUM number of copies
-P PAGE_LIST pages to print (eg 1,3-5,10)
-o media=a4 paper format
-o number-up={2|4|6|9|16} input pages per output page
-o sides=one-sided print front-page only
-o sides=two-sided-long-edge print duplex
# Show job queue
lpq -P PRINTER
# Remove pending print job.
lprm JOOBID
Control printer
# Enable/disable printer.
cupsenable PRINTER
cupsdisable PRINTER
# Accept/rejects jobs for printer.
cupsaccept PRINTER
cupsreject PRINTER
Network
ssh (1)
ssh tunnel
Abbreviations used:
LPORT: local portLADDR: local addressRPORT: remote portRADDR: remote address
The -L flag sets up a ssh tunnel to forward port LPORT on the local host to
RADDR:RPORT via the machine gateway (ssh tunnel endpoint).
# Forward local port to remote port on gateway.
ssh -L LPORT:RPORT gateway
# Forward local port to remote port on remote address via gateway.
ssh -L LPORT:RADDR:RPORT gateway
In this scenario, requests are issued on the local machine and target some remote resource, effectively making a remote resource accessible on the local machine, which may be hidden behind the tunnel endpoint (gateway).
The -R flag sets up a ssh tunnel to expose the local port LPORT as RPORT
on the remote machine gateway.
# Expose local port via remote port on gateway.
ssh -R RPORT:LPORT gateway
# Expose local port of machine with local address via remote port on gateway.
ssh -R RPORT:LADDR:LPORT gateway
In this scenario, requests are issued on the gateway and target some resource in the local network, effectively exposing the local resource on the remote machine (gateway).
The trick to memorize the syntax is to read the forwarding rules left
(source) to right (destination) while -L means that requests are issued
locally and -R means that requests are issued remotely.
The following flags are useful for setting up ssh tunnels:
-Njust stop before running the command on the remote side (w/o cmd dont drop into shell)-frunsshcommand in the background
Example
# Forward requests on localhost:8080 to moose:1234 and keep ssh in forground
# but dont drop into a shell.
ssh -N -L 8080:1234 moose
# Forward requests on moose:80 to localhost:8080 and keep ssh in forground but
# dont drop into a shell.
ssh -N -R 80:8080 moose
ssh keys
Utility script to generate ssh key pairs.
NAME=${1:?Pass new keyname as first arg}
TYPE=ed25519
FILE=${HOME}/.ssh/${NAME}-${TYPE}
if [[ -f ${FILE} || -f ${FILE}.pub ]]; then
echo "Key with name '${NAME}' already exists, remove following files explicitly:"
echo " ${FILE} ${FILE}.pub"
exit 1;
fi
set -x
ssh-keygen -C "${NAME}.${USER}@${HOSTNAME}" -f ${FILE} -t ${TYPE} -a 100
In case one needs to generate many keys at one, one can provide a passphrase by
-N "toor"or an empty one as-N "".
ssh config - ~/.ssh/config
Frequently used configs for single match.
# When ssh-ing into FOO or BAR do it as user git with given key.
host foo bar
user git
identityfile ~/.ssh/some-key
# When ssh-ing into moose actually log into host with ip addr 1.2.3.4.
# Can be used as alias for machines w/o DNS entries.
host moose
user root
port 8022
hostname 1.2.3.4
identityfile ~/.ssh/some-key
Pattern matching and evaluation order.
# For parameters, the first valued obtained will be used.
# Therefore, more host-specific blocks should come first.
host tree7
user banana
hoste tree*
user cherry
# can reference matched hostname with %h
hostname %h.some-dns-path
# ssh tree7 -> banana@tree7.some-dns-path
# ssh tree5 -> cherry@tree5.some-dns-path
ss(8)
ss [option] [filter]
[option]
-p ..... Show process using socket
-l ..... Show sockets in listening state
-4/-6 .. Show IPv4/6 sockets
-x ..... Show unix sockets
-n ..... Show numeric ports (no resolve)
-O ..... Oneline output per socket
[filter]
dport/sport PORT .... Filter for destination/source port
dst/src ADDR ........ Filter for destination/source address
and/or .............. Logic operator
==/!= ............... Comparison operator
(EXPR) .............. Group exprs
Examples
Show all tcp IPv4 sockets connecting to port 443:
ss -4 'dport 443'
Show all tcp IPv4 sockets that don't connect to port 443 or connect to address 1.2.3.4.
ss -4 'dport != 443 or dst 1.2.3.4'
tcpdump(1)
CLI
tcpdump [opts] -i <if> [<filter>]
-n Don't convert host/port names.
-w <file|-> Write pcap trace to file or stdout (-).
-r <file> Read & parse pcap file.
Some useful filters, for the full syntax see pcap-filter(7).
src <ip> Filter for source IP.
dst <ip> Filter for destination IP.
host <ip> Filter for IP (src + dst).
net <ip>/<range> Filter traffic on subnet.
[src/dst] port <port> Filter for port (optionally src/dst).
tcp/udp/icmp Filter for protocol.
Use
and/or/notand()to build filter expressions.
Examples
Capture packets from remote host
# -k: Start capturing immediately.
ssh <host> tcpdump -i any -w - | sudo wireshark -k -i -
The
anyinterface is a special keyword to capture traffic on all interfaces.
tshark (1)
tshark [opts] -i <if>
--color Colorize output.
-w <file|-> Write pcap trace to file or stdout (-).
-r <file> Read & parse pcap file.
-f <filter> Apply capture filter (see pcap-filter(7) or tcpdump).
Only applicable during capturing.
-Y <filter> Apply display filter.
Only applicable during viewing capture.
-c <count> Stop capturing after COUNT packets (INF by default).
Some useful display filters.
ip.addr != 192.168.1.0/24 Filter out whole ip subnet (source + destination).
ip.dst == 192.168.1.42 Filter for destination ip address.
tcp.dstport == 80 Filter for tcp destinatio port.
!wg Filter out all wireguard traffic.
tcp/udp/ssh/wg/... Filter for protocol.
"and/or/not/!" and "()" can be used to build filter expressions.
Use
tshak -Gto list all fields that can be used in display filters.
Examples
Capture and filter packet to file
# Capture TCP traffic with port 80 on interface eth0 to file.
sudo tshark -i eht0 -f 'tcp and port 80' -w tx.pcap
# View captured packets.
sudo tshark -r tx.pcap
# View captured packets and apply additionaly display filters.
sudo tshark -r tx.pcap -Y 'ip.addr != 192.168.1.42'
firewall-cmd(1)
Command line interface to the firewalld(1) daemon.
List current status of the firewall
# List all services and ports for all zones.
firewall-cmd --list-all
# List all services.
firewall-cmd --list-services
# List all ports.
firewall-cmd --list-ports
Add
--zone <ZONE>to limit output to a givenZONE. Use--get-zonesto see all available zones.
Add entries
# Add a service to the firewall, use `--get-services` to list all available
# service names.
firewall-cmd --add-service <SERVICE>
# Add a specific port.
firewall-cmd --add-port 8000/tcp
# Add a rich rule (eg port forwarding, dnat).
firewall-cmd --add-rich-rule 'rule family="ipv4" forward-port port="80" protocol="tcp" to-port="8080"'
Remove entries
# Remove service.
firewall-cmd --remove-service <SERVICE>
# Remove port.
firewall-cmd --remove-port 8000/tcp
# Remove rich rule.
firewall-cmd --remove-rich-rule 'rule family="ipv4" forward-port port="80" protocol="tcp" to-port="8080"'
References
- man firewall-cmd(1)
- man firewalld(1)
nftables
Nftables is a stateful Linux firewall which uses the netfilter kernel hooks. It is used for stateless, stateful packet filtering and all sorts of NAT.
Nftables is the successor to iptables.
In nftables, rules are organized with chains and tables.
chain: Ordersrules. Chains exist in two kinds:base chain: Entry point from netfilter hooks (network stack).regular chain: Can be used as jump target to group rules for better organization.
table: Groups chains together. Tables are defined by anameand anaddress family(eginet,ip,ip6, ..).
Ruleset
nft list ruleset # List all tables/chains/rules (whole ruleset).
nft flush ruleset # Clear whole ruleset.
Examples: Save rules to files and re-apply
nft list ruleset > nft.rules
nft flush ruleset
nft -f nft.rules
Example: Fully trace evaluation of nftables rules
table ip traceall {
chain filter_prerouting {
# Install chain with higher priority as the RAW standard priority.
type filter hook prerouting priority raw - 50; policy accept;
# Trace each and every packet (very verbose).
#meta nftrace set 1;
# Trace packet to port 80/81/8081 from localhost.
tcp dport { 80, 81, 8081 } ip saddr 127.0.0.1 meta nftrace set 1;
}
}
Use nft monitor trace to get trace output on tty.
Example: IPv4 port forwarding
table ip fwd {
chain nat_preroute {
# Register this chain to the PREROUTE:NAT hook (stateful packet tracking via conntrack).
type nat hook prerouting priority dstnat + 10 ; policy accept;
meta nfproto ipv4 tcp dport 81 redirect to :8081
}
}
Example: Base vs regular chain
# Table named 'playground' handling 'ip' (ipv4) address family.
table ip playground {
# Base chain.
chain filter_input_base {
# Register this chain to the INPUT:FILTER hook in the netfilter package flow.
# Specify a prioirty relative to the inbuilt 'filter' priority (smaller
# number means higher priority).
# Set the default policy to ACCEPT, to let every packet pass by default.
type filter hook input priority filter - 10; policy accept;
# Create a rule for tcp packets arriving on either port 8000 or 8100.
tcp dport { 8000, 8100 } jump input_reg_log;
# Create a rule for tcp packets arriving on port 8200.
tcp dport 8200 jump input_reg_log_all;
}
# Regular chain.
chain input_reg_log {
# Log every packet traversing this chain.
# Message lands in the kernel ring buffer.
log;
}
# Regular chain.
chain input_reg_log_all {
# Log every packet with all flags traversing this chain.
log flags all;
}
}
# Load the nf rules.
sudo nft -f playground.rules
# Create test servers.
nc -lk 0.0.0.0 8000
nc -lk 0.0.0.0 8100
nc -lk 0.0.0.0 8200
# See the nftables logging in the kernel ring buffer.
sudo dmesg -w
# Make some client connections.
nc localhost 8000
nc localhost 8200
Mental model for netfilter packet flow
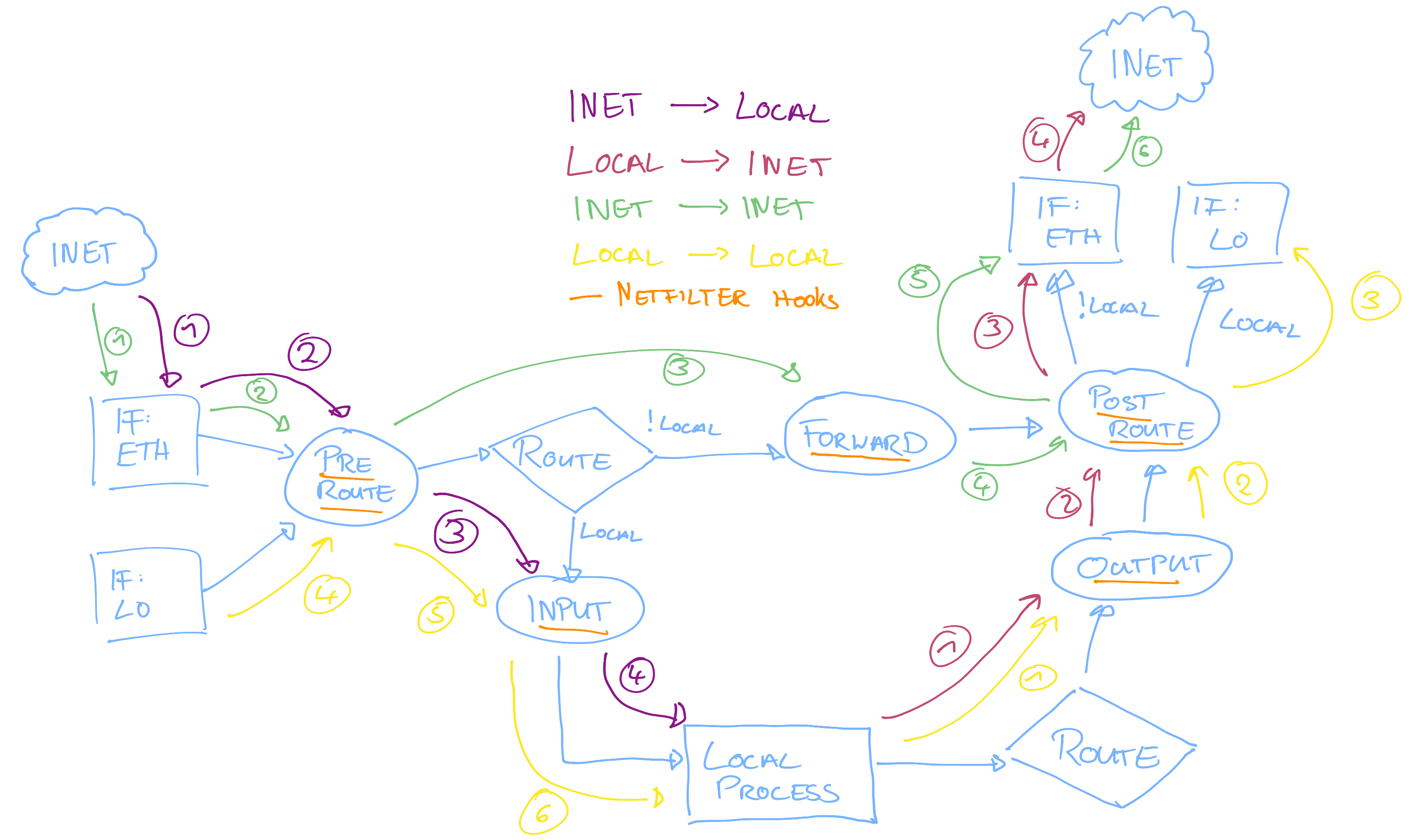
Web
html
Collapsible element
<details>
<summary>Some text goes here</summary>
... some more text goes here.
</details>
With the
openattribute<details open>the details are unfolded by default.
Minimal 2 column layout
<style>
.grid-2col {
display: grid;
grid-template-columns: 2fr 1fr;
gap: 1em
}
.col1 {
grid-column-start: 1;
background-color: red;
padding-left: 1em;
}
.col2 {
grid-column-start: 2;
background-color: green;
padding-left: 1em;
}
</style>
<div class="grid-2col">
<div class="col1">
<p>Some text in the first column.</p>
</div>
<div class="col2">
<p>Some text in the second column.</p>
</div>
</div>
Minimal grid area
<style>
.page-grid {
display: grid;
grid-template-columns: 1fr 2fr;
grid-template-areas:
"h h"
"s m"
"f f";
gap: 1em;
}
.gh {
grid-area: h;
background-color: orange;
}
.gs {
grid-area: s;
background-color: green;
}
.gm {
grid-area: m;
background-color: gray;
}
.gf {
grid-area: f;
background-color: yellow;
}
.nav-items {
display: flex; /* flexbox model => flexible layout on row */
justify-content: space-around; /* align flex boxes horizontally with space around */
align-items: center; /* center flex items vertically */
list-style: none;
}
p {
margin: 1em;
}
</style>
<div class="page-grid">
<div class="gh">
<ul class="nav-items">
<li class="nav-item"><a href="">aa</a></li>
<li class="nav-item"><a href="">bb</a></li>
<li class="nav-item"><a href="">cc</a></li>
</ul>
</div>
<div class="gs">
<p>Some text in the second column.</p>
</div>
<div class="gm">
<p>Some text in the second column.</p>
</div>
<div class="gf">
<p>Some text in the second column.</p>
</div>
</div>
Minimal tabs
<script>
const showTab = (E, T) => {
const TABS = Array.from(document.getElementsByClassName("content"));
TABS.forEach(T => {
T.style.display = "none";
});
document.getElementById(T).style.display = "block";
};
window.onload = () => {
document.getElementById("bTab1").onclick = (E) => {
showTab(E, "tTab1");
};
document.getElementById("bTab2").onclick = (E) => {
showTab(E, "tTab2");
};
}
</script>
<button type="button" id="bTab1">Tab1</button>
<button type="button" id="bTab2">Tab2</button>
<div id="tTab1" class="content" style="display: block;">
<p>Some content goes here ...</p>
</div>
<div id="tTab2" class="content" style="display: none;">
<p>... and there.</p>
</div>
Minimal tags filter
Single active filter tag
<script>
/// Map HTML elements to display kinds.
const elementToDisplay = (E) => {
switch (E.nodeName) {
case "LI":
return "list-item";
default:
return "block";
}
}
/// Display only elements with tag T.
const showTag = (T) => {
Array.from(document.getElementsByClassName("content")).forEach(E => {
E.style.display = "none";
});
Array.from(document.getElementsByClassName(T)).forEach(E => {
E.style.display = elementToDisplay(E);
});
};
/// Initialize buttons and callbacks.
window.onload = () => {
// Handle to the filter placeholder.
const filter = document.getElementById("filter");
// Create buttons for each tag T.
["arm", "x86", "clear"].forEach(T => {
const btn = document.createElement("button");
btn.innerHTML = T;
btn.onclick = T === "clear"
? (E) => {
showTag("content");
filter.innerHTML = "";
}
: (E) => {
showTag(T);
filter.innerHTML = `<p>filter: <mark>${T}</mark></p>`;
};
document.body.prepend(btn);
});
}
</script>
<div id = "filter"></div>
<ul>
<li class = "content arm">arm 1</li>
<li class = "content arm">arm 2</li>
<li class = "content arm">arm 3</li>
<li class = "content x86">x86 1</li>
<li class = "content x86">x86 2</li>
<li class = "content x86 arm">x86 + arm</li>
</ul>
<div class = "content arm">arm</div>
<div class = "content arm x86">arm x86</div>
<div class = "content x86">x86</div>
Multiple active filter tags
<script>
/// Map HTML elements to display kinds.
const elementToDisplay = (E) => {
switch (E.nodeName) {
case "LI":
return "list-item";
default:
return "block";
}
}
/// Display only elements which have all TAGS.
const showTag = (TAGS) => {
Array.from(document.getElementsByClassName("content")).forEach(E => {
// Display the element, iff the element contains every tag T in TAGS.
if (TAGS.every(T => Array.from(E.classList).includes(T))) {
E.style.display = elementToDisplay(E);
} else {
E.style.display = "none";
}
});
};
/// Initialize buttons and callbacks.
window.onload = () => {
// Handle to the filter placeholder.
const filter_node = document.getElementById("filter");
// Active filter tags.
const filter = Array();
// Create buttons for each tag T.
["arm", "x86", "clear"].forEach(T => {
const btn = document.createElement("button");
btn.innerHTML = T;
btn.onclick = T === "clear"
? (E) => {
// Clear active filter.
while (filter.length) { filter.pop(); }
showTag(["content"]);
filter_node.innerHTML = "<p>filter:</p>";
}
: (E) => {
// Toggle tag T in Active filter.
if ((idx = filter.indexOf(T)) > -1) {
filter.splice(idx, 1);
} else {
filter.push(T);
}
showTag(filter);
out = filter.map(T => `<mark>${T}</mark>`).join(" + ");
filter_node.innerHTML = `<p>filter: ${out}</p>`;
};
document.body.prepend(btn);
});
}
</script>
<div id = "filter"><p>filter:</p></div>
<ul>
<li class = "content arm">arm 1</li>
<li class = "content arm">arm 2</li>
<li class = "content arm">arm 3</li>
<li class = "content x86">x86 1</li>
<li class = "content x86">x86 2</li>
<li class = "content x86 arm">x86 + arm</li>
</ul>
<div class = "content arm">arm</div>
<div class = "content arm x86">arm x86</div>
<div class = "content x86">x86</div>
Floating figures with caption
<style>
img {
width: 100%;
height: auto;
}
figure {
width: 20%;
}
</style>
<!-- EXAMPLE 1 ---------------------------------------------------------------->
<figure style="float: left;">
<img src="grad.png">
<figcaption>Fig 1: wow such colors</figcaption>
</figure>
<p><i>
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor
incididunt ut labore et dolore magna aliqua. Nunc lobortis mattis aliquam
faucibus. A iaculis at erat pellentesque adipiscing. Dolor morbi non arcu risus
quis varius quam quisque. Fermentum odio eu feugiat pretium. Nibh nisl
condimentum id venenatis. Gravida dictum fusce ut placerat orci nulla. Pulvinar
etiam non quam lacus suspendisse faucibus interdum posuere. Pulvinar
pellentesque habitant morbi tristique senectus et netus et malesuada. Sem
fringilla ut morbi tincidunt augue interdum. Consectetur purus ut faucibus
pulvinar elementum. Dui faucibus in ornare quam. Sodales ut etiam sit amet
nisl. Nunc scelerisque viverra mauris in aliquam. Nec sagittis aliquam
malesuada bibendum arcu vitae elementum curabitur.
</i></p>
<figure style="float: right;">
<img src="grad.png">
<figcaption>Fig 2: wow such colors again</figcaption>
</figure>
<p><i>
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor
incididunt ut labore et dolore magna aliqua. Nunc lobortis mattis aliquam
faucibus. A iaculis at erat pellentesque adipiscing. Dolor morbi non arcu risus
quis varius quam quisque. Fermentum odio eu feugiat pretium. Nibh nisl
condimentum id venenatis.
</i></p>
<!-- EXAMPLE 2 ---------------------------------------------------------------->
<hr style="clear: both">
<figure style="float: left;">
<img src="grad.png">
</figure>
Floats can be next to each other on the same height.
<figure style="float: right;">
<img src="grad.png">
</figure>
<!-- EXAMPLE 3 ---------------------------------------------------------------->
<hr style="clear: both">
<figure style="float: left;">
<img src="grad.png">
</figure>
The css property <code>clear: {left, right, both};</code> controls how elements
should be handled relative to the previous floating element.
<figure style="float: right; clear: left;">
<img src="grad.png">
</figure>
<p><i>
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor
incididunt ut labore et dolore magna aliqua. Nunc lobortis mattis aliquam
faucibus. A iaculis at erat pellentesque adipiscing. Dolor morbi non arcu risus
quis varius quam quisque. Fermentum odio eu feugiat pretium. Nibh nisl
condimentum id venenatis. Gravida dictum fusce ut placerat orci nulla. Pulvinar
etiam non quam lacus suspendisse faucibus interdum posuere.
</i></p>
<!-- EXAMPLE 4 ---------------------------------------------------------------->
<hr style="clear: both">
<div style="overflow: auto; border: 2px solid red;">
<figure style="float: left;">
<img src="grad.png">
</figure>
<code>overflow: auto</code> gives an alternative to <code>clear</code> to
control placement of the floats. The red boarder visualizes the size of the
<code><div></code> block. One can remove the <code>overflow</code> property
and observe how the border changes.
</div>
<figure style="float: right;">
<img src="grad.png">
</figure>
css
selector
.moose element with class
<div class = "moose"></div> // selected
<div class = "bar"></div> // NOT selected
.moose.bar element with multiple classes
<div class = "moose bar"></div> // selected
<div class = "bar"></div> // NOT selected
.moose .bar descendant element with classes
<div class = "moose">
<div class = "bar"></div> // selected
</div>
<div class = "bar"></div> // NOT selected
p specific element
<p></p> // selected
<div></div> // NOT selected
p.bar specific element with class
<p class = "bar"></p> // selected
<p class = "foo"></p> // NOT selected
p,div any element
<p></p> // selected
<div></div> // selected
<a></a> // NOT selected
div p descendant element of other element
<div><p></p></div> // selected
<div><ul><p></p></ul></div> // NOT selected
div > o direct descendant element of other element
<div><p></p></div> // selected
<div><ul><p></p></ul></div> // NOT selected
Chart.js
Minimal example with external tooltips
<canvas id="myChart" style="margin:5em;"></canvas>
<script>
const get_or_create_tooltip = (id) => {
if (tooltip = document.getElementById(id)) {
return tooltip;
} else {
// -- Create a new Tooltip element.
const tooltip = document.createElement('div');
tooltip.id = id;
document.body.appendChild(tooltip);
// -- Some minimal styling.
tooltip.style.background = 'rgba(0, 0, 0, 0.1)';
tooltip.style.position = 'absolute';
tooltip.style.transition = 'all .2s ease';
// -- Add a table element for the tooltip content.
const table = document.createElement('table');
tooltip.appendChild(table);
return tooltip
}
}
const render_tooltip = (context) => {
const {chart, tooltip} = context;
// -- Get Tooltip element.
const tooltip_elem = get_or_create_tooltip('myTooltip');
// -- Get data point values (only one data point).
const {label: x, formattedValue: y} = tooltip.dataPoints[0];
// -- Format new tooltip.
const link = document.createElement('a');
link.href = "https://github.com/johannst";
link.innerHTML = "X:" + x + " Y:" + y;
// -- Remove previous child element and add new one.
const table = tooltip_elem.querySelector('table');
table.innerHTML = "";
table.appendChild(link);
// -- Get absolute X/Y position of the top left corner of the canvas.
const {offsetLeft: canvas_x, offsetTop: canvas_y} = chart.canvas;
// -- Set position and minimal style for the tooltip.
tooltip_elem.style.left = canvas_x + tooltip.caretX + 'px';
tooltip_elem.style.top = canvas_y + tooltip.caretY + 'px';
tooltip_elem.style.font = tooltip.options.bodyFont.string;
// -- Place the tooltip (I) left or (II) right of the data point.
if (tooltip.xAlign === "right") {
tooltip_elem.style.transform = 'translate(-100%, 0)'; // (I)
} else if (tooltip.xAlign === "left") {
tooltip_elem.style.transform = 'translate(0%, 0)'; // (II)
}
}
// -- Render a chart with some dummy data on the canvas.
const chart = new Chart(
document.getElementById('myChart'),
{
data: {
datasets: [{
// -- A single dataset.
label: 'Just some values',
type: 'scatter',
data: [
{x: 4, y: 4},
{x: 5, y: 1},
{x: 7, y: 6},
{x: 10, y: 8},
{x: 10, y: 7},
{x: 10, y: 3},
],
backgroundColor: 'rgba(255, 99, 132, 0.5)',
borderColor: 'rgb(255, 99, 132)',
}],
},
options: {
scales: {
y: {
beginAtZero: true, // -- Start the Y-Axis at zero instead min(y) of dataset.
}
},
plugins: {
tooltip: {
enabled: false, // -- Disable builtin tooltips.
mode: 'nearest', // -- Get the item that is nearest to the mouse.
intersect: false, // -- 'mode' is active also when the mouse doesnt intersect with an item on the chart.
external: render_tooltip, // -- External tooltip handler, allows to create own HTML.
}
}
}
}
);
</script>
Plotly js
Visualization library for javascript based on d3.
Official documentation is here.
Line chart example
The following is an example for a line chart which contains many options that I frequently use. It is bloated on purpose to document the options for myself.
<div id="plot-1"></div>
<script>
const commits = [ "b5a7c219", "72bb8889", "fa9e9079", "f5178ed1", "e830fa71" ]
const common_layout = {
xaxis: {
// Set range explicitly because of markers+lines mode used.
// https://stackoverflow.com/questions/46383368
range: [0, commits.length - 1],
gridcolor: "ligthgray",
rangeslider: {},
},
yaxis: {
title: "runtime in sec",
// Disable interactive y-axis zoom.
fixedrange: true,
gridcolor: "ligthgray",
},
legend: {
orientation: "h",
x: 0,
y: 1,
},
modebar: {
add: [ "hoverclosest", "hovercompare" ],
remove: [ "pan", "lasso", "select", "zoomin", "zoomout" ],
},
// Transparent plot + paper background.
plot_bgcolor: "rgba(0, 0, 0, 0)",
paper_bgcolor: "rgba(0, 0, 0, 0)",
}
const common_config = {
// Automatically resize plot when page resizes.
responsive: true,
// Dont display the plotly logo.
displaylogo: false,
}
const plot_1 = document.getElementById("plot-1")
const data_10 = {
x: commits,
y: [ 10.2, 11.4, 10.5, 11.0, 10.0 ],
name: "plot 10",
mode: "lines+markers",
}
const data_11 = {
x: commits,
y: [ 20.2, 21.4, 20.5, 21.0, 20.0 ],
name: "plot 11",
mode: "lines+markers",
}
Plotly.newPlot(plot_1, [data_10, data_11], {
...common_layout,
title: "plot-1",
}, common_config)
plot_1.on("plotly_click", data => {
if (data.points.length == 1) {
// Change page to following url.
window.location = "https://github.com/johannst/notes/commit/" + data.points[0].x
} else {
console.log("ignore click event, multiple elements selected")
}
})
</script>
Arch
cache
Caches are organized by the following components
setswaysentries
Each set consists of one or more ways and a way is a single slot which
can hold an entry.
S-set / W-way cache
+----------------- .. -----------+
SET 0 | WAY 0 | WAY 1 | | WAY W-1 |
+----------------- .. -----------+
SET 1 | WAY 0 | WAY 1 | | WAY W-1 |
+----------------- .. -----------+
.. | |
+----------------- .. -----------+
SET S-1 | WAY 0 | WAY 1 | | WAY W-1 |
+----------------- .. -----------+
In general a cache is described by the number of sets S and the number of
ways W. Depending on the values for S and W caches can be further
classified.
W=1is adirect-mappedcache, which means that each entry can be placed at exactly ONE location in the cache. It is also called a one-way set associative cache.S>1 & W>1is aW-way set associativecache, which consists of S sets where each set consists of W ways. Each entry maps to a UNIQUE set, but to ANY way in that set.S=1is afully-associativecache, which means that each entry can be placed at ANY location in the cache.
To determine which set an entry falls into, a hash function is applied on the
key which is associated with the entry. The set is then given by applying the
modulo operation to the hash value hash % num_sets.
The following figure illustrates the different cache classes and gives an
example which entries the given hash value 5 can map to.
direct-mapped 2-way set associative fully-associative
HASH=5 (IDX=5%4) HASH=5 (IDX=5%4) HASH=5 (only one IDX)
| | |
| S=4, W=1 | S=4, W=2 | S=1, W=4
| +--------+ | +--------+--------+ | +--------+--------+--------+--------+
| 0| | | 0| | | `->0| xxxxxx | xxxxxx | xxxxxx | xxxxxx |
| +--------+ | +--------+--------+ +--------+--------+--------+--------+
`- >1| xxxxxx | `->1| xxxxxx | xxxxxx |
+--------+ +--------+--------+
2| | 2| | |
+--------+ +--------+--------+
3| | 3| | |
+--------+ +--------+--------+
CPU (hardware) caches
The number of sets in a hardware cache is usually a power of two. The address
acts as the key and some bits in the address are used to select the set in the
cache. The hash function in this case is simple, as it just extracts the bits
from the address which are used to select the set.
The address is usually split up into the { TAG, IDX, OFF } bits which are
used to lookup an entry in the cache.
The IDX bits are used to index into the corresponding set, where the TAG
bits are then compared against the stored TAG bits in each way. If any way
holds an entry with the matching TAG bits, the lookup is a HIT, else a
MISS.
In case the entry is in the cache, the OFF bits are used to index into the
cache line. Hence, the number of offset bits available define the cache line
size.
The following gives an example for 64-bit addresses and a direct-mapped cache.
63 0
+-----------------------+
ADDR: | TAG | IDX | OFF |
+-----------------------+
| | `------------------,
| | |
| | CACHE |
| | +----------------+ |
| | | TAG | CACHE_LN | |
| | +----------------+ |
| | | TAG | CACHE_LN | |
| | +----------------+ |
| | | .. | |
| | +----------------+ |
| `--> | TAG | CACHE_LN | |
| +----------------+ |
| | | |
| v v |
`-------------> = + <----------`
| |
v v
HIT? DATA
OFF bits: ln2 (cache_line_sz)
IDX bits: ln2 (num_sets)
TAG bits: 64 - IDX bits - OFF bits
The total size of a cache can be computed by cache_line_sz * num_sets * num_ways.
Example
SETS: 64 => 6 IDX bits
WAYS: 8
LINE: 64 bytes => 6 OFF bits
SIZE: 64 sets * 8 ways * 64 bytes => 32k bytes
Hardware caches with virtual memory
In the context of virtual memory, caches can be placed at different location
in the memory path, either before or after the virtual address (VA) to
physical address (PA) translation. Each placement has different properties
discussed in the following.
If the cache is placed before the VA -> PA translation, it is called
virtually indexed virtually tagged (VIVT) cache, as it is indexed by a virtual
address and data in the cache is tagged with the virtual address as well.
The benefit of VIVT caches is that lookups are very fast as there is no need to wait for the result of the address translation. However, VIVT caches may suffer from the following problems.
synonyms: different VAs map to the same PA. This can happen in a single address space (same page table), if for example a process maps the same file at different VAs (also commonly referred to as aliasing or cache-line sharing). This can also happen in different address spaces (different page tables), if for example pages are shared between two processes.PT1 +-------+ | | PHYSMEM PT2 +-------+ +-------+ +-------+ | VA1 |---, | | | | +-------+ | +-------+ +-------+ | | +--->| PA1 |<-------| VA3 | +-------+ | +-------+ +-------+ | VA2 |---` | | | | +-------+ +-------+ +-------+ | | +-------+ Assume VA1 != VA2 != VA3 CACHE TAG DATA +-------+-------------+ Problems: | VA1 | Copy of PA1 | * multiple copies of the same data. | VA3 | Copy of PA1 | * write through one VA and read through a | | | different VA results in reading stale data. | VA2 | Copy of PA1 | +-------+-------------+homonyms: same VA corresponds to different PAs. This is the standard case between two different address spaces (eg in a multi-tasking os), for example if the same VA is used in two different processes, but it maps to a different PA for each process.PT1 PHYSMEM PT2 +-------+ +-------+ +-------+ | VA1 |------->| PA1 | ,---| VA2 | +-------+ +-------+ | +-------+ | | | | | | | | | +-------+ | | | | | | PA2 |<---` | | +-------+ +-------+ +-------+ Assume VA1 == VA2 CACHE TAG DATA +-------+-------------+ Problems: | VA1 | Copy of PA1 | * same VA from different address spaces map to | | | different PA | | | * read thorugh VA2 returns data from PA1 +-------+-------------+ rather than from PA2
While synonyms may lead to accessing stale data, if there is no hardware to
guarantee coherency between aliased entries, homonyms may lead to accessing
the wrong data.
On one hand there are multiple counter measures to avoid homonyms, for example
physical tagging, tags could contain an address space identifier (ASID), or the
cache could be flushed on context switches (changing the page table).
Approaches like physical tagging and ASIDs work, as the same VA always maps to
the same index in the cache, which would then result in a cache miss in case of
the homonym.
Preventing synonyms on the other hand is harder, as neither physical tagging
nor ASIDs help in this case. Flushing the cache during context switches only
helps with the case where different address spaces alias shared pages, but it
won't help if the same PA is aliased by different VAs in a single address space.
There are to alternative approaches, one is to have hardware support to detect
synonyms and the other one is to have the operating system only allow shared
mappings with VAs that have the same index bits for the cache. However, the
latter only works for direct-mapped caches, as there is only a single location
where those VAs could map to in the cache.
If the cache is placed after the VA -> PA translation, it is called
physically indexed physically tagged (PIPT) cache, as it is indexed by a
physical address and data in the cache is tagged with the physical address as
well.
Compared to VIVT caches, PIPT caches do not suffer from synonyms or
homonyms. However, their major drawback is that the lookup depends on the
result of the address translation, and hence the translation and the cache
lookup happen sequentially which greatly decreases access latency.
Between VIVT and PIPT caches there is also a hybrid approach called virtually indexed physically tagged (VIPT) cache, where the cache lookup is done with a
virtual address and the data is tagged with the physical address.
The benefit of this approach is that the cache lookup and the address
translation can be done in parallel, and due to the physical tagging, homonyms
are not possible.
For VIPT caches, synonyms may still happen depending on how the cache is
constructed.
- if the
indexbits for the cache lookup, exceed thepage offsetin the virtual address, thensynonymsare still possible. - if all the
indexbits for the cache lookup fall into thepage offsetof the virtual address, then the bits used for the cache lookup won't change during theVA -> PAtranslation, and hence the cache effectively operates as a PIPT cache. The only downside is that the number of sets in the cache is limited by the page size.
VIPT as PIPT example
The following example shows that for a system with 4k pages and cache lines of
64 bytes a VIPT cache can have at most 64 sets to still act as PIPT cache.
63 12 0
+-----------------------+
VA: | | PG_OFF |
+-----------------------+
CACHE BITS: | C_IDX | C_OFF |
+---------------+
PAGE SIZE : 4k
PAGE OFFSET: ln (PAGE SIZE) = 12 bits
CACHE LINE : 64 bytes
CACHE OFFSET: ln (CACHE LINE) = 6 bits
CACHE INDEX: PG_OFF - C_OFF = 6 bits
CACHE SETS : 2^CACHE INDEX = 64 sets
The total cache size can be increased by adding additional ways, however that also has a practical upper limit, as adding more ways reduces the latency.
Cache info in Linux
# Info about different caches (size, ways, sets, type, ..).
lscpu -C
# NAME ONE-SIZE ALL-SIZE WAYS TYPE LEVEL SETS PHY-LINE COHERENCY-SIZE
# L1d 32K 128K 8 Data 1 64 1 64
# L1i 32K 128K 8 Instruction 1 64 1 64
# L2 256K 1M 4 Unified 2 1024 1 64
# L3 6M 6M 12 Unified 3 8192 1 64
# Info about how caches are shared between cores / hw-threads. Identified by
# the same cache ids on the same level.
lscpu -e
# CPU CORE L1d:L1i:L2:L3 ONLINE
# 0 0 0:0:0:0 yes
# 1 1 1:1:1:0 yes
# 4 0 0:0:0:0 yes
# 5 1 1:1:1:0 yes
#
# => CPU 0,4 share L1d, L1i, L2 caches (here two hw-threads of a core).
x86_64
keywords: x86_64, x86, abi
- 64bit synonyms:
x86_64,x64,amd64,intel 64 - 32bit synonyms:
x86,ia32,i386 - ISA type:
CISC - Endianness:
little
Registers
General purpose register
bytes
[7:0] [3:0] [1:0] [1] [0] desc
----------------------------------------------------------
rax eax ax ah al accumulator
rbx ebx bx bh bl base register
rcx ecx cx ch cl counter
rdx edx dx dh dl data register
rsi esi si - sil source index
rdi edi di - dil destination index
rbp ebp bp - bpl base pointer
rsp esp sp - spl stack pointer
r8-15 rNd rNw - rNb
Special register
bytes
[7:0] [3:0] [1:0] desc
---------------------------------------------------
rflags eflags flags flags register
rip eip ip instruction pointer
FLAGS register
rflags
bits desc instr comment
--------------------------------------------------------------------------------------------------------------
[21] ID identification ability to set/clear -> indicates support for CPUID instr
[18] AC alignment check alignment exception for PL 3 (user), requires CR0.AM
[13:12] IOPL io privilege level
[11] OF overflow flag
[10] DF direction flag cld/std increment (0) or decrement (1) registers in string operations
[9] IF interrupt enable cli/sti
[7] SF sign flag
[6] ZF zero flag
[4] AF auxiliary carry flag
[2] PF parity flag
[0] CF carry flag
Change flag bits with pushf / popf instructions:
pushfd // push flags (4bytes) onto stack
or dword ptr [esp], (1 << 18) // enable AC flag
popfd // pop flags (4byte) from stack
There is also
pushfq/popfqto push and pop all 8 bytes ofrflags.
Model Specific Register (MSR)
rdmsr // Read MSR register, effectively does EDX:EAX <- MSR[ECX]
wrmsr // Write MSR register, effectively does MSR[ECX] <- EDX:EAX
See guest64-msr.S as an example.
Some interesting MSRs
C000_0082: IA32_LSTARtarget address forsyscallinstruction in IA-32e (64 bit) mode.C000_0100: IA32_FS_BASEstorage for %fs segment base address.C000_0101: IA32_GS_BASEstorage for %gs segment base address.C000_0102: IA32_KERNEL_GS_BASEadditional register,swapgsswaps GS_BASE and KERNEL_GS_BASE, without altering any register state. Can be used to swap in a pointer to a kernel data structure on syscall entry, as for example inentry_SYSCALL_64.
Current privilege level
The current privilege level can be found at any time in the last two bits of the
code segment selector cs. The following shows an example debugging an entry
and exit of a syscall in x86_64-linux.
Breakpoint 1, entry_SYSCALL_64 () at arch/x86/entry/entry_64.S:90
90 swapgs
(gdb) info r rax rcx cs
rax 0x0 0 ; syscall nr
rcx 0x7feb16399e56 140647666916950 ; ret addr
cs 0x10 16 ; cs & 0x3 -> 0 (ring0,kernel)
(gdb) c
Breakpoint 2, entry_SYSCALL_64 () at arch/x86/entry/entry_64.S:217
217 sysretq
(gdb) info r rcx cs
rcx 0x7feb16399e56 140647666916950 ; ret addr
cs 0x10 16 ; cs & 0x3 -> 0 (ring0,kernel)
(gdb) b *$rcx
(gdb) s
Breakpoint 3, 0x00007feb16399e56 in ?? ()
(gdb) info r cs
cs 0x33 51 ; cs & 0x3 -> 3 (ring3,user)
Size directives
Explicitly specify size of the operation.
mov byte ptr [rax], 0xff // save 1 byte(s) at [rax]
mov word ptr [rax], 0xff // save 2 byte(s) at [rax]
mov dword ptr [rax], 0xff // save 4 byte(s) at [rax]
mov qword ptr [rax], 0xff // save 8 byte(s) at [rax]
Addressing
mov qword ptr [rax], rbx // save val in rbx at [rax]
mov qword ptr [imm], rbx // save val in rbx at [imm]
mov rax, qword ptr [rbx+4*rcx] // load val at [rbx+4*rcx] into rax
rip relative addressing:
lea rax, [rip+.my_str] // load addr of .my_str into rax
...
.my_str:
.asciz "Foo"
Load effective address:
mov rax, 2
lea r11, [rax + 3] // r11 <- 5
String instructions
The operand size of a string instruction is defined by the instruction suffix
b | w | d | q.
Source and destination registers are modified according to the direction flag (DF) in the flags register
DF=0increment src/dest registersDF=1decrement src/dest registers
Following explanation assumes byte operands with DF=0:
movsb // move data from string to string
// ES:[DI] <- DS:[SI]
// DI <- DI + 1
// SI <- SI + 1
lodsb // load string
// AL <- DS:[SI]
// SI <- SI + 1
stosb // store string
// ES:[DI] <- AL
// DI <- DI + 1
cmpsb // compare string operands
// DS:[SI] - ES:[DI] ; set status flag (eg ZF)
// SI <- SI + 1
// DI <- DI + 1
scasb // scan string
// AL - ES:[DI] ; set status flag (eg ZF)
// DI <- DI + 1
String operations can be repeated:
rep // repeat until rcx = 0
repz // repeat until rcx = 0 or while ZF = 0
repnz // repeat until rcx = 0 or while ZF = 1
Example: Simple memset
// memset (dest, 0xaa /* char */, 0x10 /* len */)
lea di, [dest]
mov al, 0xaa
mov cx, 0x10
rep stosb
AT&T syntax for intel syntax users
mov %rax, %rbx // mov rbx, rax
mov $12, %rax // mov rax, 12
mov (%rsp), %rax // mov rax, [rsp]
mov 8(%rsp), %rax // mov rax, [rsp + 8]
mov (%rsp,%rcx,4), %rax // mov rax, [rsp + 8 * rcx]
mov 0x100, %rax // mov rax, [0x100]
mov (0x100), %rax // mov rax, [0x100]
mov %gs:8, %rax // mov rax, gs:8
Time stamp counter - rdtsc
static inline uint64_t rdtsc() {
uint32_t eax, edx;
asm volatile("rdtsc" : "=d"(edx), "=a"(eax)::);
return (uint64_t)edx << 32 | eax;
}
Constant TSC behavior ensures that the duration of each clock tick is uniform and supports the use of the TSC as a wall clock timer even if the processor core changes frequency. This is the architectural behavior moving forward.
- 18.17 TIME-STAMP COUNTER - intel64-vol3
On linux one can check the constant_tsc cpu flag, to validate if the
implemented TSC ticks with a constant frequency.
grep constant_tsc /proc/cpuinfo
Cpu & hw features - cpuid
cpuid // in: eax leaf; ecx sub-leaf
// out: eax, ebx, ecx, edx (interpreting depends on leaf)
This instruction is used to query for availability of certain instructions or hardware details like cache sizes and son on.
An example how to read cpuid leafs is show in cpuid.c.
SysV x86_64 ABI
Passing arguments to functions
- Integer/Pointer arguments
reg arg ----------- rdi 1 rsi 2 rdx 3 rcx 4 r8 5 r9 6 - Floating point arguments
reg arg ----------- xmm0 1 .. .. xmm7 8 - Additional arguments are passed on the stack. Arguments are pushed
right-to-left (RTL), meaning next arguments are closer to current
rsp.
Return values from functions
- Integer/Pointer return values
reg size ----------------- rax 64 bit rax+rdx 128 bit - Floating point return values
reg size ------------------- xmm0 64 bit xmm0+xmm1 128 bit
Caller saved registers
Caller must save these registers if they should be preserved across function calls.
raxrcxrdxrsirdirspr8-r11
Callee saved registers
Caller can expect these registers to be preserved across function calls. Callee must must save these registers in case they are used.
rbxrbpr12–r15
Stack
- grows downwards
- frames aligned on 16 byte boundary
Hi ADDR | +------------+ | | prev frame | | +------------+ <--- 16 byte aligned (X & ~0xf) | [rbp+8] | saved RIP | | [rbp] | saved RBP | | [rbp-8] | func stack | | | ... | v +------------+ Lo ADDR
Function prologue & epilogue
- prologue
push rbp // save caller base pointer mov rbp, rsp // save caller stack pointer - epilogue
mov rsp, rbp // restore caller stack pointer pop rbp // restore caller base pointerEquivalent to
leaveinstruction.
Windows x64 ABI
Passing arguments to functions (ref)
A single argument is never spread across multiple registers.
- Integer/Pointer arguments
reg arg ----------- rcx 1 rdx 2 r8 3 r9 4 - Floating point arguments
reg arg ----------- xmm0 1 .. .. xmm3 4 - Additional arguments are passed on the stack. Arguments are pushed
right-to-left (RTL), meaning next arguments are closer to current
rsp. See example.
Return values from functions
- Integer/Pointer return values
reg size ----------------- rax 64 bit - Floating point return values
reg size ------------------- xmm0 64 bit
Caller saved registers
Caller must save these registers if they should be preserved across function calls.
raxrcxrdxr8-r11xmm0-xmm5
Callee saved registers
Caller can expect these registers to be preserved across function calls. Callee must must save these registers in case they are used.
rbxrbprdirsirspr12-r15xmm6-xmm15
ASM skeleton - linux userspace
Small assembler skeleton, ready to use with following properties:
- use raw Linux syscalls (
man 2 syscallfor ABI) - no
C runtime (crt) - gnu assembler
gas - intel syntax
// file: greet.S
#include <asm/unistd.h>
.intel_syntax noprefix
.section .text, "ax", @progbits
.global _start
_start:
mov rdi, 1 # fd (stdout)
lea rsi, [rip + greeting] # buf
mov rdx, [rip + greeting_len] # count
mov rax, __NR_write # write(2) syscall nr
syscall
mov rdi, __NR_exit # exit code
mov rax, 60 # exit(2) syscall nr
syscall
.section .rdonly, "a", @progbits
greeting:
.ascii "Hi ASM-World!\n"
greeting_len:
.int .-greeting
Files with
.Ssuffix are pre-processed, while files with.ssuffix are not.
To compile and run:
> gcc -o greet greet.S -nostartfiles -nostdlib && ./greet
Hi ASM-World!
MBR boot sectors example
The following shows a non-minimal MBR boot sector, which transitions from 16-bit real mode to 32-bit protected mode by setting up a small global descriptor table (GDT). A string is printed in each mode.
.code16
.intel_syntax noprefix
.section .boot, "ax", @progbits
// Disable interrupts.
cli
// Clear segment selectors.
xor ax, ax
mov ds, ax
mov es, ax
mov ss, ax
mov fs, ax
mov gs, ax
// Set cs to 0x0000, as some BIOSes load the MBR to either 07c0:0000 or 0000:7c000.
jmp 0x0000:entry_rm16
entry_rm16:
// Set video mode 3h, see [1].
// * 80x25 text mode
// * 640x200 pixel resolution (8x8 pixel per char)
// * 16 colors (4bit)
// * 4 pages
// * 0xB8000 screen address
//
// [1] http://www.ctyme.com/intr/rb-0069.htm
mov ax, 0x3
int 0x10
// Move cursor to second row.
// http://www.ctyme.com/intr/rb-0087.htm
mov ah, 0x02
mov bh, 0 // page
mov dh, 1 // row
mov dl, 0 // col
int 0x10
// Clear direction flag for lodsb below.
cld
// Load pointer to msg_rm string (null terminated).
lea si, [msg_rm]
// Teletype output char at current cursor position.
// http://www.ctyme.com/intr/rb-0106.htm
mov ah, 0x0e
1:
lodsb // al <- ds:si ; si+=1 ; (al char to write)
test al,al // test for null terminator
jz 2f
int 0x10
jmp 1b
2:
// Enable A20 address line.
in al, 0x92
or al, 2
out 0x92, al
// Load GDT descriptor.
lgdt [gdt_desc]
// Enable protected mode (set CR0.PE bit).
mov eax, cr0
or eax, (1 << 0)
mov cr0, eax
// Far jump which loads segment selector (0x0008) into cs.
// 0x0008 -> RPL=0, TI=0(GDT), I=1
jmp 0x0008:entry_pm32
.code32
entry_pm32:
// Select data segment selector (0x0010) for ds.
mov ax, gdt_data - gdt
mov ds, ax
// Write through VGA interface (video memory).
// Each character is represented by 2 bytes.
// 4 bit bg | 4 bit fg | 8 bit ascii char
//
// Start writing at third line.
mov edi, 0xb8000 + (80 * 2 * 2)
lea esi, [msg_pm]
1:
lodsb // al <- ds:esi ; esi+=1
test al, al // test for null terminator
jz 2f
or eax, 0x1f00 // blue bg, white fg
stosw // ds:[edi] <- ax; edi+=2
jmp 1b
2:
hlt
jmp 2b
// For simplicity keep data used by boot sector in the same section.
.balign 8
msg_rm:
.asciz "Hello from Real Mode!"
msg_pm:
.asciz "Hello from Protected Mode!"
.balign 8
gdt:
.8byte 0x0000000000000000 // 0x00 | null descriptor
.8byte 0x00cf9a000000ffff // 0x08 | 32 bit, code (rx), present, dpl=0, g=4K, base=0, limit=fffff
gdt_data:
.8byte 0x00cf92000000ffff // 0x10 | 32 bit, data (rw), present, dpl=0, g=4K, base=0, limit=fffff
gdt_desc:
.2byte .-gdt-1 // size
.4byte gdt // address
// Write MBR boot magic value.
.fill 510 - (. - .boot), 1, 0x00
.2byte 0xaa55
The linker script.
OUTPUT_FORMAT(elf32-i386)
OUTPUT_ARCH(i386)
SECTIONS {
. = 0x7c00;
.boot : { *(.boot) }
_boot_end = .;
/DISCARD/ : { *(.*) }
ASSERT(_boot_end - 0x7c00 == 512, "boot sector must be exact 512 bytes")
}
The build instructions.
mbr: mbr.ld mbr.o
ld -o $@.elf -nostdlib -T $^
objcopy -O binary $@.elf $@
mbr.o: mbr.S
gcc -c -o $@ -m32 -ffreestanding $^
One can boot into the bootsector from legacy BIOS, either with qemu or by writing the mbr boot sector as first sector onto a usb stick.
qemu-system-i386 -hda mbr
The following gives some more detailed description for the segment selector registers, the segment descriptors in the GDT, and the GDT descriptor itself.
# Segment Selector (cs, ds, es, ss, fs, gs).
[15:3] I Descriptor Index
[2] TI Table Indicator (0=GTD | 1=LDT)
[1:0] RPL Requested Privilege Level
# Segment Descriptor (2 x 4 byte words).
0x4 [31:24] Base[31:24]
0x4 [23] G Granularity, scaling of limit (0=1B | 1=4K)
0x4 [22] D/B (0=16bit | 1=32bit)
0x4 [21] L (0=compatibility mode | 1=64bit code) if 1 -> D/B = 0
0x4 [20] AVL Free use for system sw
0x4 [19:16] Limit[19:16]
0x4 [15] P Present
0x4 [14:13] DPL Descriptor privilege level
0x4 [12] S (0=system segment | 1=code/data)
0x4 [11:0] Type Code or data and access information.
0x4 [7:0] Base[23:16]
0x0 [31:16] Base[15:0]
0x0 [15:0] Limit[15:0]
# GDT descriptor (32bit mode)
[47:16] Base address of GDT table.
[15:0] Length of GDT table.
In 64-bit mode the
{cs, ds, es, ss}segment register have no effect, segmentation is effectively disabled. The{gs, fs}segment register however can still be used for segmented memory access in 64-bit with paging enabled. Segmentation takes place before VA -> PA address translation.The example in seg.c shows how to set the
gsbase address and to relative accesses.
References
- SystemV AMD64 ABI
- AMD64 Vol1: Application Programming
- AMD64 Vol2: System Programming
- AMD64 Vol3: General-Purpose & System Instructions
- X86_64 Cheat-Sheet
- Intel 64 Vol1: Basic Architecture
- Intel 64 Vol2: Instruction Set Reference
- Intel 64 Vol3: System Programming Guide
- GNU Assembler
- GNU Assembler Directives
- GNU Assembler
x86_64dependent features juicebox-asmanx86_64jit assembler playground- zig x86 bare metal examples
armv8
keywords: aarch64, arm64, A64, aarch32, A32, T32, abi
The armv8 architecture introduces support for 64-bit and defines two
execution states aarch64 and aarch32.
Implementations are not required to implement all execution states for all
exception levels (EL). For example the coretex-a32 only
implements aarch32, while the coretex-a34 only implements
aarch64.
The execution states support different instruction sets.
aarch64only supports the newA64instruction set, where all instructions have the fixed size of of 32 bits.aarch32supports theA32andT32instruction sets. These are updated versions of thearmv7instruction sets, kept backwards compatible allowingarmv7programs to run onarmv8.In
armv7the instruction setsA32anT32were calledarmandthumbrespectively.
A program always runs in either the aarch64 or the aarch32 execution
state, but never in a mixture of both. Transitions between execution states
only occur when raising or lowering the exception level.
aarch64 -> aarch32can only occur when switching from higher EL to lower EL.aarch32 -> aarch64can only occur when switching from lower EL to higher EL.
The following figure depicts which execution state Transitions are allowed.
(user) EL0 ^ |
(os) EL1 | 32->64
(hypervisor) EL2 64->32 |
(secure) EL3 | v
This means for example, an os running in aarch32 can only support aarch32
user applications, while an os running in aarch64 can support
aarch32 / aarch64 user applications.
arm64
This page only talks about the 64 bit part of the
armv8architecture. For an overview seearmv8.
keywords: arm64, aarch64, abi
- 64bit synonyms:
arm64,aarch64 - ISA type:
RISC - Endianness:
little,big
Registers
General purpose registers
bytes
[7:0] [3:0] desc
---------------------------------------------
x0-x28 w0-w28 general purpose registers
x29 w29 frame pointer (FP)
x30 w30 link register (LR)
sp wsp stack pointer (SP)
pc program counter (PC)
xzr wzr zero register
Write to
wNregister clears upper 32bit.
Special registers per EL
bytes
[7:0] desc
---------------------------------------------
sp_el0 stack pointer EL0
sp_el1 stack pointer EL1
elr_el1 exception link register EL1
spsr_el1 saved process status register EL1
sp_el2 stack pointer EL2
elr_el2 exception link register EL2
spsr_el2 saved process status register EL2
sp_el3 stack pointer EL3
elr_el3 exception link register EL3
spsr_el3 saved process status register EL3
Instructions cheatsheet
Accessing system registers
Reading from system registers:
mrs x0, vbar_el1 // move vbar_el1 into x0
Writing to system registers:
msr vbar_el1, x0 // move x0 into vbar_el1
Control Flow
b <offset> // relative forward/back branch
br <Xn> // absolute branch to address in register Xn
// branch & link, store return address in X30 (LR)
bl <offset> // relative forward/back branch
blr <Xn> // absolute branch to address in register Xn
ret {Xn} // return to address in X30, or Xn if supplied
Addressing
Offset
ldr x0, [x1] // x0 = [x1]
ldr x0, [x1, 8] // x0 = [x1 + 8]
ldr x0, [x1, x2, lsl #3] // x0 = [x1 + (x2<<3)]
ldr x0, [x1, w2, stxw] // x0 = [x1 + sign_ext(w2)]
ldr x0, [x1, w2, stxw #3] // x0 = [x1 + (sign_ext(w2)<<3)]
Shift amount can either be
0orlog2(access_size_bytes). Eg for 8byte access it can either be{0, 3}.
Index
ldr x0, [x1, 8]! // pre-inc : x1+=8; x0 = [x1]
ldr x0, [x1], 8 // post-inc: x0 = [x1]; x1+=8
Pair access
ldp x1, x2, [x0] // x1 = [x0]; x2 = [x0 + 8]
stp x1, x2, [x0] // [x0] = x1; [x0 + 8] = x2
Procedure Call Standard ARM64 (aapcs64)
Passing arguments to functions
- Integer/Pointer arguments
reg arg ----------- x0 1 .. .. x7 8 - Additional arguments are passed on the stack. Arguments are pushed
right-to-left (RTL), meaning next arguments are closer to currentsp.void take(..., int a9, int a10); | | | ... | Hi | +-->| a10 | | +---------->| a9 | <-SP | +-----+ v | ... | Lo
Return values from functions
- Integer/Pointer return values
reg size ----------------- x0 64 bit
Callee saved registers
x19-x28SP
Stack
- full descending
- full:
sppoints to the last used location (valid item) - descending: stack grows downwards
- full:
spmust be 16byte aligned when used to access memory for r/wspmust be 16byte aligned on public interface interfaces
Frame chain
- linked list of stack-frames
- each frame links to the frame of its caller by a
frame record- a frame record is described as a
(FP,LR)pair
- a frame record is described as a
x29 (FP)must point to the frame record of the current stack-frame+------+ Hi | 0 | frame0 | +->| 0 | | | | ... | | | +------+ | | | LR | frame1 | +--| FP |<-+ | | ... | | | +------+ | | | LR | | current | x29 ->| FP |--+ frame v | ... | Lo- end of the frame chain is indicated by following frame record
(0,-) - location of the frame record in the stack frame is not specified
Function prologue & epilogue
- prologue
sub sp, sp, 16 stp x29, x30, [sp] // [sp] = x29; [sp + 8] = x30 mov x29, sp // FP points to frame record - epilogue
ldp x29, x30, [sp] // x29 = [sp]; x30 = [sp + 8] add sp, sp, 16 ret
ASM skeleton
Small assembler skeleton, ready to use with following properties:
- use raw Linux syscalls (
man 2 syscallfor ABI) - no
C runtime (crt) - gnu assembler
gas
// file: greet.S
#include <asm/unistd.h> // syscall NRs
.arch armv8-a
.section .text, "ax", @progbits
.balign 4 // align code on 4byte boundary
.global _start
_start:
mov x0, 2 // fd
ldr x1, =greeting // buf
ldr x2, =greeting_len // &len
ldr x2, [x2] // len
mov w8, __NR_write // write(2) syscall
svc 0
mov x0, 0 // exit code
mov w8, __NR_exit // exit(2) syscall
svc 0
.balign 8 // align data on 8byte boundary
.section .rodata, "a", @progbits
greeting:
.asciz "Hi ASM-World!\n"
greeting_len:
.int .-greeting
man gcc:
file.Sassembler code that must be preprocessed.
To cross-compile and run:
> aarch64-linux-gnu-g++ -o greet greet.S -nostartfiles -nostdlib \
-Wl,--dynamic-linker=/usr/aarch64-linux-gnu/lib/ld-linux-aarch64.so.1 \
&& qemu-aarch64 ./greet
Hi ASM-World!
Cross-compiling on
Ubuntu 20.04 (x86_64), paths might differ on other distributions. Explicitly specifying the dynamic linker should not be required when compiling natively on arm64.
References
- Procedure Call Standard ARM64
- ARMv8-A Programmer's Guide
- ARMv8-A Architecture Reference Manual
- AppNote: ARMv8 Bare-metal boot code
- GNU Assembler
- GNU Assembler Directives
- GNU Assembler
AArch64dependent features - ARM64-A Instruction Browser
armv7a
keywords: arm, armv7, abi
- ISA type:
RISC - Endianness:
little,big
Registers
General purpose registers
bytes
[3:0] alt desc
---------------------------------------------
r0-r12 general purpose registers
r11 fp
r13 sp stack pointer
r14 lr link register
r15 pc program counter
Special registers
bytes
[3:0] desc
---------------------------------------------
cpsr current program status register
CPSR register
cpsr
bits desc
-----------------------------
[31] N negative flag
[30] Z zero flag
[29] C carry flag
[28] V overflow flag
[27] Q cummulative saturation (sticky)
[9] E load/store endianness
[8] A disable asynchronous aborts
[7] I disable IRQ
[6] F disable FIQ
[5] T indicate Thumb state
[4:0] M process mode (USR, FIQ, IRQ, SVC, ABT, UND, SYS)
Instructions cheatsheet
Accessing system registers
Reading from system registers:
mrs r0, cpsr // move cpsr into r0
Writing to system registers:
msr cpsr, r0 // move r0 into cpsr
Control Flow
b <lable> // relative forward/back branch
bl <lable> // relative forward/back branch & link return addr in r14 (LR)
// branch & exchange (can change between ARM & Thumb instruction set)
// bit Rm[0] == 0 -> ARM
// bit Rm[0] == 1 -> Thumb
bx <Rm> // absolute branch to address in register Rm
blx <Rm> // absolute branch to address in register Rm &
// link return addr in r14 (LR)
Load/Store
Different addressing modes.
ldr r1, [r0] // r1 = [r0]
ldr r1, [r0, #4] // r1 = [r0+4]
ldr r1, [r0, #4]! // pre-inc : r0+=4; r1 = [r0]
ldr r1, [r0], #4 // post-inc: [r0] = r1; r0+=4
ldr r0, [r1, r2, lsl #3] // r0 = [r1 + (r2<<3)]
Load/store multiple registers full-descending.
stmfd r0!, {r1-r2, r5} // r0-=4; [r0]=r5
// r0-=4; [r0]=r2
// r0-=4; [r0]=r1
ldmfd r0!, {r1-r2, r5} // r1=[r0]; r0+=4
// r2=[r0]; r0+=4
// r5=[r0]; r0+=4
!is optional but has the effect to update the base pointer registerr0here.
Push/Pop
push {r0-r2} // effectively stmfd sp!, {r0-r2}
pop {r0-r2} // effectively ldmfd sp!, {r0-r2}
Procedure Call Standard ARM (aapcs32)
Passing arguments to functions
- integer/pointer arguments
reg arg ----------- r0 1 .. .. r3 4 - a double word (64bit) is passed in two consecutive registers (eg
r1+r2) - additional arguments are passed on the stack. Arguments are pushed
right-to-left (RTL), meaning next arguments are closer to currentsp.void take(..., int a5, int a6); | | | ... | Hi | +-->| a6 | | +---------->| a5 | <-SP | +-----+ v | ... | Lo
Return values from functions
- integer/pointer return values
reg size ----------------- r0 32 bit r0+r1 64 bit
Callee saved registers
r4-r11sp
Stack
- full descending
- full:
sppoints to the last used location (valid item) - descending: stack grows downwards
- full:
spmust be 4byte aligned (word boundary) at all timespmust be 8byte aligned on public interface interfaces
Frame chain
- not strictly required by each platform
- linked list of stack-frames
- each frame links to the frame of its caller by a
frame record- a frame record is described as a
(FP,LR)pair (2x32bit)
- a frame record is described as a
r11 (FP)must point to the frame record of the current stack-frame+------+ Hi | 0 | frame0 | +->| 0 | | | | ... | | | +------+ | | | LR | frame1 | +--| FP |<-+ | | ... | | | +------+ | | | LR | | current | r11 ->| FP |--+ frame v | ... | Lo- end of the frame chain is indicated by following frame record
(0,-) - location of the frame record in the stack frame is not specified
r11is not updated before the new frame record is fully constructed
Function prologue & epilogue
- prologue
push {fp, lr} mov fp, sp // FP points to frame record - epilogue
pop {fp, pc} // pop LR directly into PC
ASM skeleton
Small assembler skeleton, ready to use with following properties:
- use raw Linux syscalls (
man 2 syscallfor ABI) - no
C runtime (crt) - gnu assembler
gas
// file: greet.S
#include <asm/unistd.h> // syscall NRs
.arch armv7-a
.section .text, "ax"
.balign 4
// Emit `arm` instructions, same as `.arm` directive.
.code 32
.global _start
_start:
// Branch with link and exchange instruction set.
blx _do_greet
mov r0, #0 // exit code
mov r7, #__NR_exit // exit(2) syscall
swi 0x0
// Emit `thumb` instructions, same as `.thumb` directive.
.code 16
.thumb_func
_do_greet:
mov r0, #2 // fd
ldr r1, =greeting // buf
ldr r2, =greeting_len // &len
ldr r2, [r2] // len
mov r7, #__NR_write // write(2) syscall
swi 0x0
// Branch and exchange instruction set.
bx lr
.balign 8 // align data on 8byte boundary
.section .rodata, "a"
greeting:
.asciz "Hi ASM-World!\n"
greeting_len:
.int .-greeting
man gcc:
file.Sassembler code that must be preprocessed.
To cross-compile and run:
> arm-linux-gnueabi-gcc -o greet greet.S -nostartfiles -nostdlib \
-Wl,--dynamic-linker=/usr/arm-linux-gnueabi/lib/ld-linux.so.3 \
&& qemu-arm ./greet
Hi ASM-World!
Cross-compiling on
Ubuntu 20.04 (x86_64), paths might differ on other distributions. Explicitly specifying the dynamic linker should not be required when compiling natively on arm.
References
- Procedure Call Standard ARM
- ARMv7-A Programmer's Guide
- ARMv7-A Architecture Reference Manual
- GNU Assembler
- GNU Assembler Directives
- GNU Assembler
ARMdependent features
riscv
keywords: rv32, rv64
- ISA type:
RISC - Endianness:
little,big
Registers
- riscv32 =>
XLEN=32 - riscv64 =>
XLEN=64
General purpose registers
[XLEN-1:0] abi name desc
---------------------------------------------
x0 zero zero register
x1 ra return addr
x2 sp stack ptr
x3 gp global ptr
x4 tp thread ptr
x5-x7 t0-t2 temp regs
x8-x9 s0-s1 saved regs
x10-x17 a0-a7 arg regs
x18-x27 s2-s11 saved regs
x28-x31 t3-t6 temp regs
ASM skeleton
Small assembler skeleton, ready to use with following properties:
- use raw Linux syscalls (
man 2 syscallfor ABI) - no
C runtime (crt) - gnu assembler
gas
// file: greet.S
#include <asm/unistd.h> // syscall NRs
.section .text, "ax", @progbits
.balign 4 // align code on 4byte boundary
.global _start
_start:
li a0, 2 // fd
la a1, greeting // buf
ld a2, (greeting_len) // &len
li a7, __NR_write // write(2) syscall
ecall
li a0, 42 // exit code
li a7, __NR_exit // exit(2) syscall
ecall
.balign 8 // align data on 8byte boundary
.section .rodata, "a", @progbits
greeting:
.asciz "Hi ASM-World!\n"
greeting_len:
.int .-greeting
man gcc:
file.Sassembler code that must be preprocessed.
To cross-compile and run:
> riscv64-linux-gnu-gcc -o greet greet.S -nostartfiles -nostdlib \
-Wl,--dynamic-linker=/usr/riscv64-linux-gnu/lib/ld-linux-riscv64-lp64d.so.1 \
&& qemu-riscv64 ./greet
Hi ASM-World!
Cross-compiling on
Ubuntu 20.04 (x86_64), paths might differ on other distributions. Explicitly specifying the dynamic linker should not be required when compiling natively on riscv.Select dynamic linker according to abi used during compile & link.